
খুব বেশি চমক ছাড়াই, মেটা লামা 3 সিরিজের মডেলগুলির সাথে "রাস্তায় উড়িয়ে দিতে" এসেছিল, যা "ইতিহাসের সবচেয়ে শক্তিশালী ওপেন সোর্স বড় মডেল" হিসাবে পরিচিত।
বিশেষভাবে, মেটা-তে ওপেন সোর্সড বিভিন্ন আকারের দুটি মডেল রয়েছে, 8B এবং 70B৷
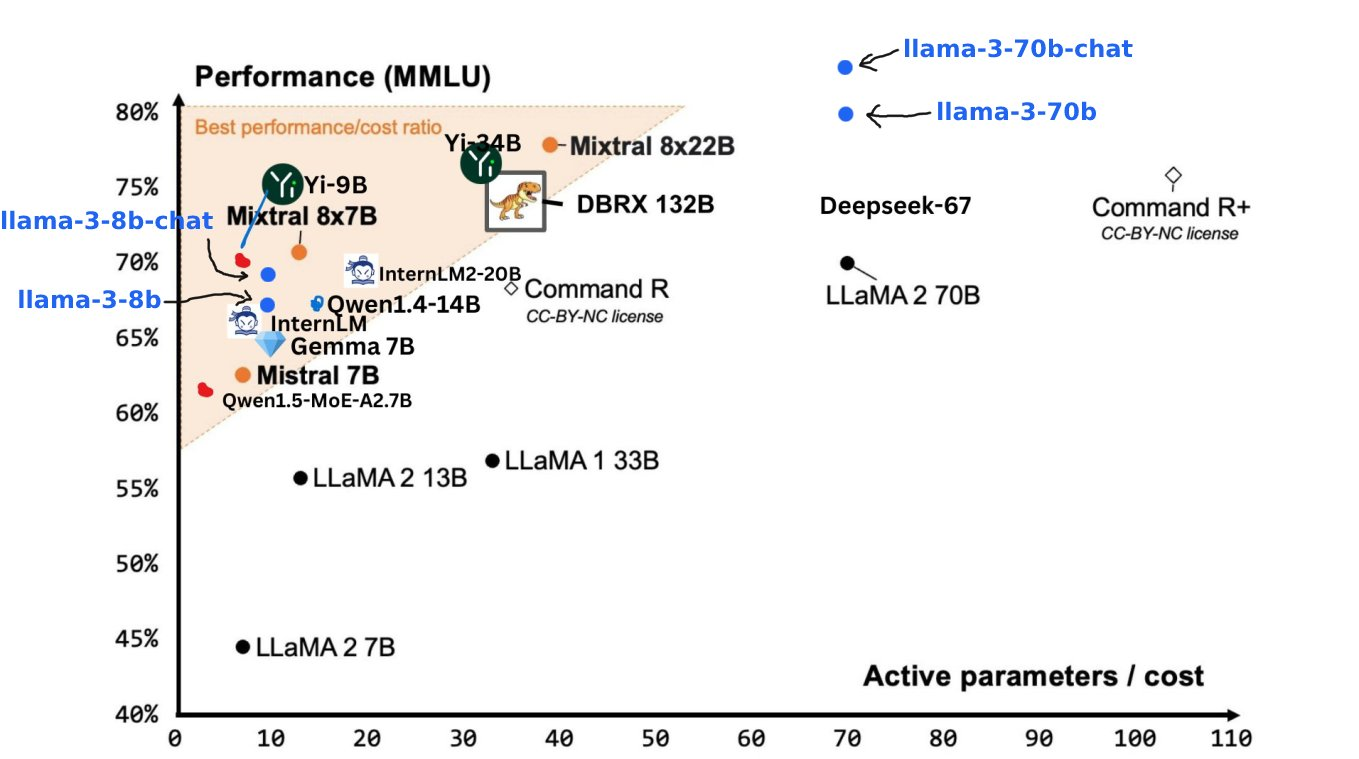
- Llama 3 8B: মূলত Llama 2 70B এর মতই শক্তিশালী।
- Llama 3 70B: প্রথম স্তরের AI মডেল, Gemini 1.5 Pro-এর সাথে তুলনীয়, সমস্ত দিক থেকে Claude Big Cup-কে ছাড়িয়ে গেছে
উপরোক্ত শুধু মেটা এর ক্ষুধা, আসল খাবার এখনও আসা বাকি. আগামী কয়েক মাসের মধ্যে, মেটা ধারাবাহিকভাবে মাল্টি-মডেল, বহু-ভাষা সংলাপ, দীর্ঘ প্রসঙ্গ উইন্ডো এবং অন্যান্য ক্ষমতা সহ নতুন মডেলগুলির একটি সিরিজ চালু করবে, তাদের মধ্যে, 400B-এর উপরে হেভিওয়েট খেলোয়াড় Claude 3 সুপার কাপের সাথে প্রতিদ্বন্দ্বিতা করবে বলে আশা করা হচ্ছে। .
Llama 3 অভিজ্ঞতার ঠিকানা: https://llama.meta.com/llama3/

আরেকটি GPT-4 স্তরের মডেল এখানে, Llama 3 খোলা আছে
আগের Llama 2 মডেলের সাথে তুলনা করে, Llama 3 একটি নতুন স্তরে পৌঁছেছে বলা যেতে পারে।
প্রি-ট্রেনিং এবং পোস্ট-ট্রেনিং-এর উন্নতির জন্য ধন্যবাদ, এই সময়ে প্রকাশিত প্রাক-প্রশিক্ষণ এবং নির্দেশনা ফাইন-টিউনিং মডেলগুলি হল 8B এবং 70B প্যারামিটার স্কেলের সবচেয়ে শক্তিশালী মডেল, একই সময়ে, পোস্টের অপ্টিমাইজেশন -প্রশিক্ষণ প্রক্রিয়া মডেলের ত্রুটির হারকে উল্লেখযোগ্যভাবে হ্রাস করেছে, মডেলের সামঞ্জস্য বাড়ায় এবং প্রতিক্রিয়ার বৈচিত্র্যকে সমৃদ্ধ করে।
জুকারবার্গ একবার একটি পাবলিক বক্তৃতায় প্রকাশ করেছিলেন যে ব্যবহারকারীরা হোয়াটসঅ্যাপে মেটা এআই কোডিং-সম্পর্কিত প্রশ্ন জিজ্ঞাসা করবেন না তা বিবেচনা করে, এই ক্ষেত্রে Llama 2-এর অপ্টিমাইজেশন অসামান্য নয়।
এই সময়, Llama 3 যুক্তি, কোড তৈরি এবং নির্দেশাবলী অনুসরণ করার ক্ষেত্রে যুগান্তকারী উন্নতি অর্জন করেছে, এটিকে আরও নমনীয় এবং ব্যবহার করা সহজ করে তুলেছে।
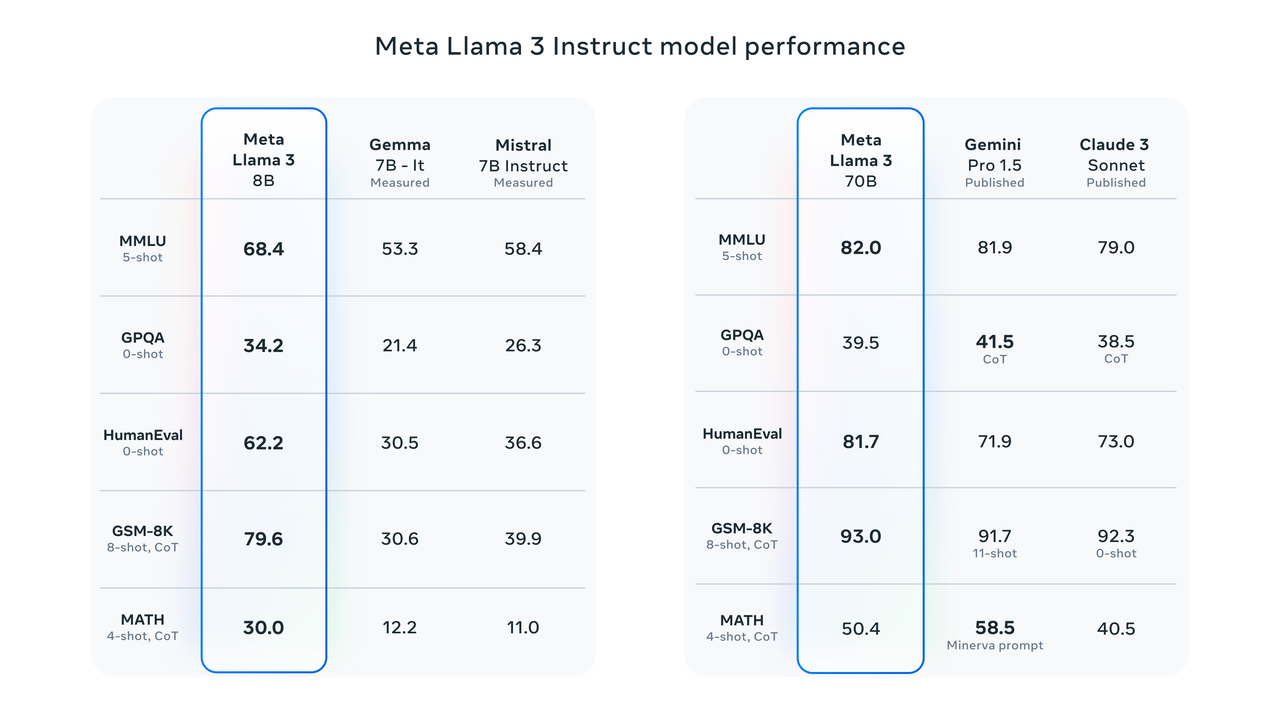
বেঞ্চমার্ক পরীক্ষার ফলাফল দেখায় যে MMLU, GPQA, HumanEval এবং অন্যান্য পরীক্ষায় Llama 3 8B Google Gemma 7B এবং Mistral 7B নির্দেশের চেয়ে অনেক বেশি স্কোর করেছে। জুকারবার্গের ভাষায়, সবচেয়ে ছোট লামা 3 মূলত সবচেয়ে বড় লামা 2 এর মতো শক্তিশালী।
Llama 3 70B শীর্ষস্থানীয় AI মডেলগুলির মধ্যে রয়েছে এর সামগ্রিক কর্মক্ষমতা ক্লাউড 3-এর তুলনায় ভাল।
বেঞ্চমার্কের অধীনে মডেলের কর্মক্ষমতা সঠিকভাবে অধ্যয়ন করতে, মেটা একটি নতুন উচ্চ-মানের মানব মূল্যায়ন ডেটাসেটও তৈরি করেছে।
মূল্যায়ন সেটটিতে 12টি মূল ব্যবহারের ক্ষেত্রে 1800টি প্রম্পট রয়েছে: পরামর্শের জন্য জিজ্ঞাসা করা, মগজ স্টর্মিং, শ্রেণীকরণ, বন্ধ প্রশ্নোত্তর, কোডিং, সৃজনশীল লেখা, নিষ্কাশন, ব্যক্তিত্ব, খোলা প্রশ্নোত্তর, যুক্তি, পুনর্লিখন এবং সংক্ষিপ্তকরণ।

Llama 3 কে এই মূল্যায়ন সেটে ওভারফিটিং থেকে আটকাতে, মেটা এমনকি তাদের গবেষণা দলটিকে এই ডেটাসেট অ্যাক্সেস করা থেকে নিষিদ্ধ করেছে। Claude Sonnet, Mistral Medium এবং GPT-3.5-এর সাথে একের পর এক প্রতিযোগিতায়, Meta Llama 70B একটি "অপ্রতিরোধ্য বিজয়" দিয়ে প্রতিযোগিতা শেষ করেছে।
মেটা অফিসিয়াল ভূমিকা অনুযায়ী, Llama 3 তার মডেল আর্কিটেকচারে একটি অপেক্ষাকৃত আদর্শ বিশুদ্ধ ডিকোডার ট্রান্সফরমার আর্কিটেকচার বেছে নিয়েছে। Llama 2 এর সাথে তুলনা করে, Llama 3 এর বেশ কয়েকটি মূল উন্নতি রয়েছে:
- Llama 3 একটি 128K টোকেন শব্দভান্ডার সহ একটি টোকেনাইজার ব্যবহার করে ভাষাকে আরও দক্ষতার সাথে এনকোড করতে, উল্লেখযোগ্যভাবে মডেলের কর্মক্ষমতা উন্নত করে।
- গ্রুপড কোয়েরি অ্যাটেনশন (GQA) Llama 3 মডেলের অনুমান দক্ষতা উন্নত করতে 8B এবং 70B উভয় মডেলেই ব্যবহৃত হয়।
- মডেলটিকে 8192 টোকেনের অনুক্রমের উপর প্রশিক্ষিত করা হয়, যাতে স্ব-মনোযোগ নথির সীমানা অতিক্রম না করে তা নিশ্চিত করতে মুখোশ ব্যবহার করে।
প্রশিক্ষণ তথ্যের পরিমাণ এবং গুণমান পরবর্তী পর্যায়ে বড় মডেল ক্ষমতার উত্থান প্রচারের মূল কারণ।
শুরু থেকেই, মেটা লামা 3 সম্ভাব্য সবচেয়ে শক্তিশালী মডেল হিসাবে ডিজাইন করা হয়েছিল। মেটা প্রি-ট্রেনিং ডেটাতে প্রচুর বিনিয়োগ করে। জানা গেছে যে Llama 3 পাবলিক সোর্স থেকে সংগৃহীত 15T এর বেশি টোকেন ব্যবহার করে, যা Llama 2 দ্বারা ব্যবহৃত ডেটা সেটের সাতগুণ এবং এতে থাকা কোড ডেটা Llama 2-এর চারগুণ।

বহু-ভাষার ব্যবহারিক প্রয়োগ বিবেচনা করে, Llama 3 প্রাক-প্রশিক্ষণ ডেটা সেটের 5% এরও বেশি 30টিরও বেশি ভাষা কভার করে উচ্চ-মানের নন-ইংরেজি ডেটা থাকে তবে, মেটা কর্মকর্তারাও স্বীকার করেছেন যে ইংরেজির সাথে তুলনা করে এই ভাষাগুলির মধ্যে এটি কিছুটা নিকৃষ্ট বলে আশা করা হচ্ছে।
Llama 3 সর্বোচ্চ মানের ডেটা সম্পর্কে প্রশিক্ষিত হয়েছে তা নিশ্চিত করার জন্য, মেটা গবেষণা দল এমনকি হিউরিস্টিক ফিল্টার, NSFW ফিল্টার, শব্দার্থক ডিডুপ্লিকেশন পদ্ধতি এবং টেক্সট ক্লাসিফায়ারগুলি ডেটার গুণমানের পূর্বাভাস দেওয়ার জন্য আগে থেকেই ব্যবহার করে।
এটি লক্ষণীয় যে গবেষণা দলটি আরও দেখেছে যে লামা মডেলগুলির পূর্ববর্তী প্রজন্মগুলি উচ্চ-মানের ডেটা সনাক্ত করতে আশ্চর্যজনকভাবে ভাল ছিল, তাই তারা Llama 2 কে Llama 3 দ্বারা সমর্থিত পাঠ্য মানের শ্রেণীবদ্ধকারীর জন্য প্রশিক্ষণ ডেটা তৈরি করতে দেয়, সত্যিকার অর্থে "AI প্রশিক্ষণ AI" "
প্রশিক্ষণের মানের পাশাপাশি, লামা 3 প্রশিক্ষণের দক্ষতায় একটি কোয়ান্টাম লিপও করেছে।
মেটা প্রকাশ করেছে যে বৃহত্তম লামা 3 মডেলকে প্রশিক্ষণ দেওয়ার জন্য, তারা তিনটি ধরণের সমান্তরালকরণকে একত্রিত করেছে: ডেটা সমান্তরালকরণ, মডেল সমান্তরালকরণ এবং পাইপলাইন সমান্তরালকরণ।
16K GPU-তে একযোগে প্রশিক্ষণের সময়, প্রতি GPU-এ 400 TFLOPS কম্পিউট ব্যবহার করা যেতে পারে। গবেষণা দলটি দুটি কাস্টম-নির্মিত 24K GPU ক্লাস্টারে প্রশিক্ষণ পরিচালনা করেছে।

GPU আপটাইম সর্বাধিক করার জন্য, গবেষণা দল একটি উন্নত নতুন প্রশিক্ষণ স্ট্যাক তৈরি করেছে যা ত্রুটি সনাক্তকরণ, পরিচালনা এবং রক্ষণাবেক্ষণ স্বয়ংক্রিয় করে। উপরন্তু, মেটা ব্যাপকভাবে হার্ডওয়্যার নির্ভরযোগ্যতা এবং নীরব ডেটা দুর্নীতি সনাক্তকরণ প্রক্রিয়া উন্নত করেছে, এবং চেকপয়েন্ট এবং রোলব্যাকের ওভারহেড কমাতে একটি নতুন স্কেলেবল স্টোরেজ সিস্টেম তৈরি করেছে।
এই উন্নতিগুলি সামগ্রিকভাবে কার্যকর প্রশিক্ষণের সময়কে 95%-এর বেশি করে তোলে এবং Llama 3-এর প্রশিক্ষণ দক্ষতাকে পূর্ববর্তী প্রজন্মের তুলনায় প্রায় তিনগুণ বেশি করে তোলে।
আরও প্রযুক্তিগত বিবরণের জন্য, দয়া করে মেটার অফিসিয়াল ব্লগটি দেখুন: https://ai.meta.com/blog/meta-llama-3/
ওপেন সোর্স VS ক্লোজড সোর্স
মেটার "পুত্র" হিসাবে, লামা 3 স্বাভাবিকভাবেই এআই চ্যাটবট মেটা এআই-তে একত্রিত হয়েছে।
গত বছরের মেটা কানেক্ট 2023 সম্মেলনের সময়, জুকারবার্গ আনুষ্ঠানিকভাবে মিটিংয়ে মেটা এআই চালু করার ঘোষণা দেন এবং তারপর দ্রুত এটিকে মার্কিন যুক্তরাষ্ট্র, অস্ট্রেলিয়া, কানাডা, সিঙ্গাপুর, দক্ষিণ আফ্রিকা এবং অন্যান্য অঞ্চলে প্রচার করেন।
আগের সাক্ষাত্কারে, জুকারবার্গ Llama 3 দিয়ে সজ্জিত Meta AI সম্পর্কে আরও বেশি আত্মবিশ্বাসী ছিলেন, বলেছিলেন যে এটি হবে সবচেয়ে বুদ্ধিমান AI সহকারী যা লোকেরা বিনামূল্যে ব্যবহার করতে পারে।
আমি মনে করি এটি একটি চ্যাটবট-এর মতো বিন্যাস থেকে এমন একটিতে চলে যাবে যেখানে আপনি কেবল একটি প্রশ্ন জিজ্ঞাসা করতে পারেন এবং এটি আপনাকে একটি উত্তর দেবে এবং আপনি এটিকে আরও জটিল কাজ দিতে পারেন এবং এটি সেই কাজগুলি সম্পূর্ণ করবে।
মেটা এআই ওয়েব অভিজ্ঞতার ঠিকানা সংযুক্ত করা হয়েছে: https://www.meta.ai/

অবশ্যই, যদি Meta AI "এখনও আপনার দেশে/অঞ্চলে উপলব্ধ না হয়", তাহলে আপনি ওপেন সোর্স মডেল ব্যবহার করার জন্য সবচেয়ে সহজ চ্যানেলটি ব্যবহার করতে পারেন – Hugging Face, বিশ্বের বৃহত্তম AI ওপেন সোর্স কমিউনিটি ওয়েবসাইট।
অভিজ্ঞতার ঠিকানা সংযুক্ত করা হল: https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct
বিভ্রান্তি, পো এবং অন্যান্য প্ল্যাটফর্মগুলিও দ্রুত প্ল্যাটফর্ম পরিষেবাগুলিতে লামা 3-কে একীভূত করার ঘোষণা দিয়েছে।

আপনি ওপেন সোর্স মডেল প্ল্যাটফর্মের প্রতিলিপি API ইন্টারফেস কল করেও Llama 3-এর অভিজ্ঞতা নিতে পারেন, এর ব্যবহারের মূল্যও প্রকাশ করা হয়েছে, তাই আপনি এটিকে চাহিদা অনুযায়ী ব্যবহার করতে পারেন।
মজার বিষয় হল, মেটা আনুষ্ঠানিকভাবে Llama 3 ঘোষণা করার আগে, তীক্ষ্ণ দৃষ্টিসম্পন্ন নেটিজেনরা আবিষ্কার করেছিল যে Microsoft এর Azure মার্কেট Llama 3 8B Instruct সংস্করণটি চুরি করেছে তবে, খবরটি আরও ছড়িয়ে পড়ার সাথে সাথে, যখন নেটিজেনরা আবার লিঙ্কটি অ্যাক্সেস করার চেষ্টা করেছিল, তখন আমি যা পেয়েছি "404" পৃষ্ঠা।
বর্তমানে পুনরুদ্ধার করা হয়েছে: https://azuremarketplace.microsoft.com/en-us/marketplace/apps/metagenai.meta-llama-3-8b-chat-offer?tab=overview
লামা 3-এর আগমন সোশ্যাল প্ল্যাটফর্ম X-এ আলোচনার একটি নতুন ঝড় তুলেছে।
মেটা এআই প্রধান বিজ্ঞানী এবং টুরিং পুরষ্কার বিজয়ী ইয়ান লেকুন শুধুমাত্র লামা 3 প্রকাশের জন্য উল্লাস করেননি, তবে আবারও ভবিষ্যদ্বাণী করেছেন যে আগামী কয়েক মাসের মধ্যে আরও সংস্করণ চালু করা হবে। এমনকি মাস্ক কমেন্ট এরিয়াতে হাজির হন এবং লামা 3 এর জন্য তার স্বীকৃতি এবং প্রত্যাশা একটি সংক্ষিপ্ত এবং অন্তর্নিহিত "খারাপ নয়।"
NVIDIA-এর একজন প্রবীণ বিজ্ঞানী, JIM Fan, তার দৃষ্টিতে Llama 3 400B+ এর উপর মনোযোগ কেন্দ্রীভূত করেছেন, তার মতে, Llama 3 প্রযুক্তিগত অগ্রগতি থেকে দূরে সরে গেছে এবং এটি ওপেন সোর্স মডেল এবং শীর্ষ ক্লোজড সোর্স মডেলের প্রতীক। .
এটি শেয়ার করা বেঞ্চমার্ক পরীক্ষা থেকে, এটি দেখা যায় যে Llama 3 400B+ এর শক্তি প্রায় ক্লাউড এক্সট্রা লার্জ কাপ এবং GPT-4 টার্বো-এর নতুন সংস্করণের সাথে তুলনা করা যায় যদিও এখনও একটি নির্দিষ্ট ফাঁক রয়েছে, এটি প্রমাণ করার জন্য যথেষ্ট এটি শীর্ষ বড় মডেলের মধ্যে একটি স্থান আছে.

আজ স্ট্যানফোর্ড ইউনিভার্সিটির একজন প্রফেসর এবং এআই-এর একজন শীর্ষ বিশেষজ্ঞ অ্যান্ড্রু এনজি-এর জন্মদিনের সঙ্গে মিল রয়েছে।
এটা বলতে হবে যে আজকের ওপেন সোর্স মডেলটি সত্যিই একশটি ফুল ফুটতে দিচ্ছে এবং একশত চিন্তাধারাকে বিতর্কিত করছে।
এই বছরের শুরুতে, জুকারবার্গ, যার হাতে 350,000 জিপিইউ রয়েছে, দ্য ভার্জের সাথে একটি সাক্ষাত্কারে দৃঢ় সুরে মেটার দৃষ্টিভঙ্গি বর্ণনা করেছেন – AGI (কৃত্রিম সাধারণ বুদ্ধিমত্তা) তৈরিতে প্রতিশ্রুতিবদ্ধ।
ওপেনএআই-এর বিপরীতে, যা খোলা নয়, মেটা ওপেন সোর্স রুট বরাবর AGI-এর হলি গ্রেইলের দিকে চার্জ চালু করেছে।
জুকারবার্গ যেমন বলেছেন, মেটা, যা দৃঢ়ভাবে ওপেন সোর্স, এই চ্যালেঞ্জিং যাত্রায় কিছুই লাভ করেনি:
আমি সাধারণত মনে করি যে ওপেন সোর্স সম্প্রদায়ের জন্য ভাল এবং আমাদের জন্য ভাল কারণ আমরা উদ্ভাবন থেকে উপকৃত হই।
বিগত বছরে, পুরো এআই সার্কেলটি ওপেন সোর্স বা ক্লোজড সোর্স রুটকে ঘিরে অবিরাম বিতর্ক করে চলেছে এই বিতর্কটি প্রযুক্তিগত স্তরে সুবিধা এবং অসুবিধাগুলির তুলনার বাইরে চলে গেছে এবং AI এর ভবিষ্যতের বিকাশের মূল দিককে স্পর্শ করেছে। এমনকি মাস্ক, যিনি ব্যক্তিগতভাবে বাইরে গিয়েছিলেন, ওপেন সোর্স Grok 1.0 দ্বারা বিশ্বে একটি পার্থক্য তৈরি করেছেন।
কিছুক্ষণ আগে, কিছু মতামত বলেছিল যে ওপেন সোর্স মডেলটি ক্রমবর্ধমান পশ্চাদপদ হয়ে উঠবে এখন লামা 3-এর আগমন এই হতাশাবাদী দৃষ্টিভঙ্গিকে মুখে একটি থাপ্পড় দিয়েছে।
যাইহোক, যদিও Llama 3 ওপেন সোর্স মডেলে কিছুটা স্বস্তি এনেছে, ওপেন সোর্স বনাম ক্লোজড সোর্স নিয়ে এই বিতর্কের শেষ নেই।
সর্বোপরি, GPT-4.5/5, যা গোপনে লঞ্চ করার প্রস্তুতি নিচ্ছে, এই গ্রীষ্মে অপ্রতিদ্বন্দ্বী পারফরম্যান্সের সাথে এই দীর্ঘ বিতর্কের অবসান ঘটাতে পারে৷
# Aifaner এর অফিসিয়াল WeChat পাবলিক অ্যাকাউন্ট অনুসরণ করতে স্বাগতম: Aifaner (WeChat ID: ifanr) যত তাড়াতাড়ি সম্ভব আপনাকে আরও উত্তেজনাপূর্ণ সামগ্রী সরবরাহ করা হবে।