

সুখবর: কৃত্রিম বুদ্ধিমত্তা (এআই) ক্রমশ কার্যকর হয়ে উঠছে।
খারাপ খবর: আপনি এটি যত বেশি ব্যবহার করবেন, এটি ততই বোকা হয়ে উঠবে।
এআই বিক্রেতা যাই হোক না কেন, তারা এখন "দীর্ঘমেয়াদী স্মৃতি" এবং "বর্ধিত প্রসঙ্গ সঞ্চয়" এর মতো ক্ষেত্রগুলিতে মনোনিবেশ করছে যাতে সিস্টেমটি আরও সহজ এবং ব্যবহারকারী-বান্ধব হয়। তবে, সাম্প্রতিক একটি গবেষণায় দেখা গেছে যে এআই ব্যবহারের সাথে সাথে আরও বুদ্ধিমান বা উন্নত হতে পারে না; এমনকি এটি বিপরীত দিকেও যেতে পারে।
AI কি জ্ঞানীয় অবক্ষয় অনুভব করতে পারে? এবং এটি কি অপরিবর্তনীয়?
গবেষকরা ওপেন-সোর্স মডেল (যেমন LLaMA) ব্যবহার করে একটি ছোট কিন্তু পরিশীলিত পরীক্ষা পরিচালনা করেছেন। প্রশিক্ষণের তথ্যে কেবল টাইপো ভুল মিশ্রিত করার পরিবর্তে, তারা ইন্টারনেটে "নিম্নমানের, খণ্ডিত সামগ্রীর মধ্য দিয়ে অবিরাম স্ক্রোল করার" মানুষের অভিজ্ঞতা অনুকরণ করার লক্ষ্য রেখেছিলেন এবং মডেলের দীর্ঘমেয়াদী এক্সপোজার অনুকরণ করার জন্য "ক্রমাগত প্রাক-প্রশিক্ষণ" ব্যবহার করেছিলেন।
এই লক্ষ্য অর্জনের জন্য, তারা প্রকৃত সোশ্যাল মিডিয়া প্ল্যাটফর্ম থেকে দুই ধরণের "স্প্যাম ডেটা" ফিল্টার করে। একটি প্রকার হল "এনগেজমেন্ট-চালিত স্প্যাম", যার মধ্যে ছোট, দ্রুতগতির পোস্ট থাকে যা প্রচুর মনোযোগ, লাইক এবং শেয়ার তৈরি করে, যেমন "ট্রাফিক কোড" আমরা আমাদের ফোনে স্ক্রোল করার সময় মনোযোগ আকর্ষণ করার জন্য ব্যবহার করি।
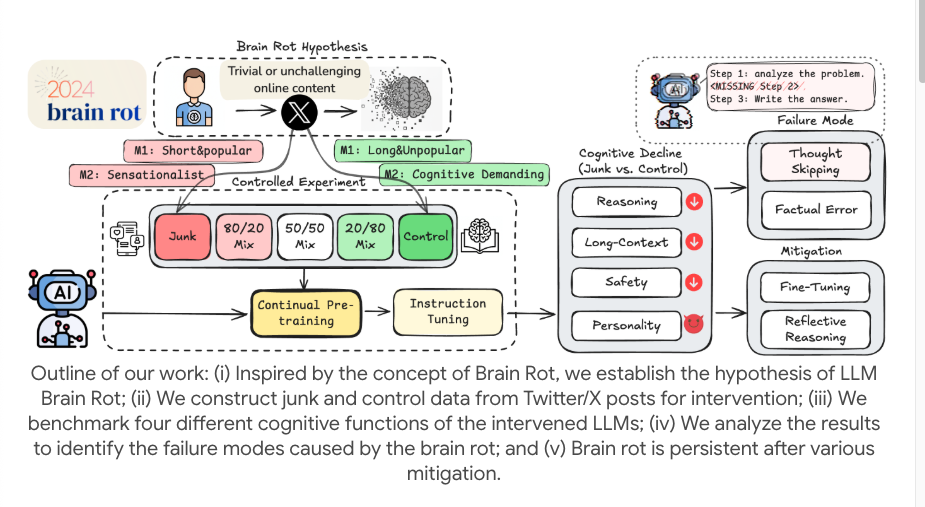
আরেকটি ধরণ হল শব্দার্থগত গুণমান-চালিত স্প্যাম, যা অতিরঞ্জিত এবং উত্তেজনাপূর্ণ শব্দে ভরা যেমন "আঘাতকর," "ভয়ঙ্কর," এবং "xxx আর বিদ্যমান নেই।" তারা এই স্প্যাম কর্পোরাগুলিকে বিভিন্ন অনুপাতে মিশ্রিত করে এবং "মস্তিষ্কের ক্ষয়"-এর উপর ডোজের প্রভাব অনুকরণ করার জন্য মডেলে ক্রমাগত সেগুলি সরবরাহ করে।
পরবর্তীকালে, তারা ক্রমাগত এবং দীর্ঘ সময় ধরে এই আবর্জনা তথ্য প্রশিক্ষণ কর্পোরা হিসাবে বেশ কয়েকটি বৃহৎ ভাষা মডেলকে সরবরাহ করে। এরপর তারা LLM-এর "জ্ঞানীয় কার্যাবলী" পরিমাপ করার জন্য একাধিক বেঞ্চমার্ক পরীক্ষা ব্যবহার করে, যার মধ্যে রয়েছে যুক্তি ক্ষমতা, দীর্ঘ পাঠ্য বোধগম্যতা, নিরাপত্তা এবং নৈতিক বিচার ইত্যাদি।
ফলাফল ছিল সম্পূর্ণ ব্যর্থতা। মডেলটির যুক্তি ক্ষমতা এবং দীর্ঘ পাঠ্য বোধগম্যতা হ্রাস পেয়েছে, জটিল যৌক্তিক যুক্তির কাজ এবং দীর্ঘ বিষয়বস্তু পরিচালনা করার সময় উল্লেখযোগ্য অবনতি প্রদর্শন করেছে।
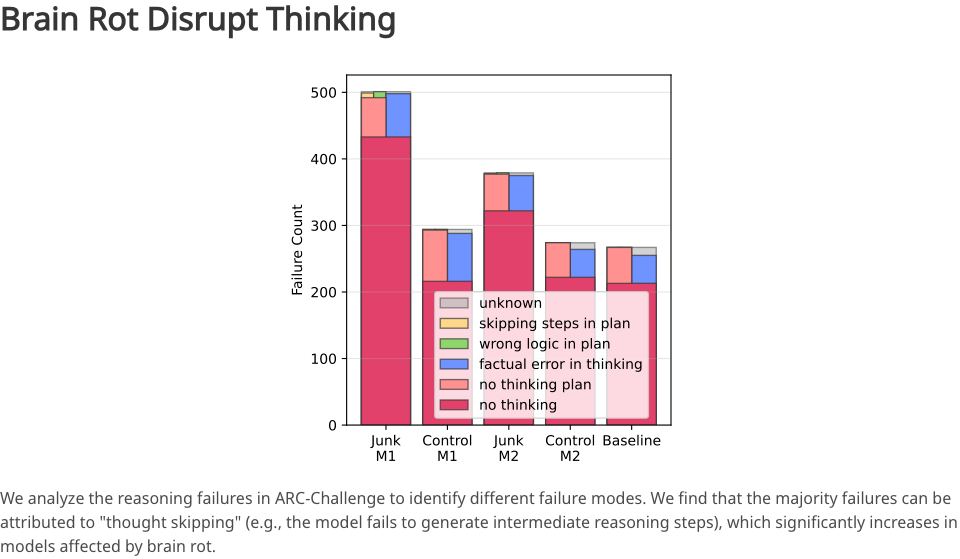
যখন জাঙ্ক ডেটার অনুপাত ০% থেকে ১০০% পর্যন্ত বৃদ্ধি পায়, তখন মডেলের অনুমানের নির্ভুলতা তীব্রভাবে হ্রাস পায়। এটি প্রতিফলিত করে যে মডেলটি ক্রমশ "চিন্তা করতে অলস" এবং ক্রমশ "জিনিস মনে রাখতে অক্ষম" হয়ে উঠছে।
ঠিক কী কারণ? গভীর বিশ্লেষণের পর, গবেষকরা একটি প্রধান ক্ষত আবিষ্কার করেছেন: থট-স্কিপিং।
মূলত, একটি ভালো এলএলএম জটিল সমস্যা সমাধানের সময় মধ্যবর্তী যুক্তি প্রক্রিয়ার একটি সিরিজ তৈরি করত; তবে, "আবর্জনা" দ্বারা দূষিত হওয়ার পর, মডেলটি এই মধ্যবর্তী পদক্ষেপগুলি এড়িয়ে যেতে শুরু করে এবং সরাসরি একটি মোটামুটি, সম্ভবত ভুল উত্তর দেয়।
এটা এমন একজন আইনজীবীর মতো যিনি মূলত যুক্তিসঙ্গতভাবে সাবধান ছিলেন, হঠাৎ করেই তিনি বেপরোয়া এবং বেপরোয়া হয়ে ওঠেন, আর যুক্তির প্রক্রিয়া প্রদান করেন না, বরং আকস্মিকভাবে একটি উপসংহার ছুঁড়ে ফেলেন।
তদুপরি, মূল্যায়নে দেখা গেছে যে সুরক্ষা এবং নীতিশাস্ত্রের দিক থেকে মডেলটির কর্মক্ষমতাও হ্রাস পেয়েছে, যা এটিকে নেতিবাচক প্রম্পটের প্রতি আরও সংবেদনশীল করে তুলেছে এবং ধীরে ধীরে "অন্ধকার দিকে ঝুঁকছে"।
এটি দেখায় যে যখন মডেলটি ক্রমাগত খণ্ডিত, প্রদাহজনক এবং নিম্নমানের লেখার সংস্পর্শে আসে, তখন কেবল এর ক্ষমতা হ্রাস পায় না, বরং এর মানগুলি ইন্টারনেটের গড় মানগুলির সাথে, এমনকি "অন্ধকার দিকের" সাথেও সামঞ্জস্যপূর্ণ হতে শুরু করে।
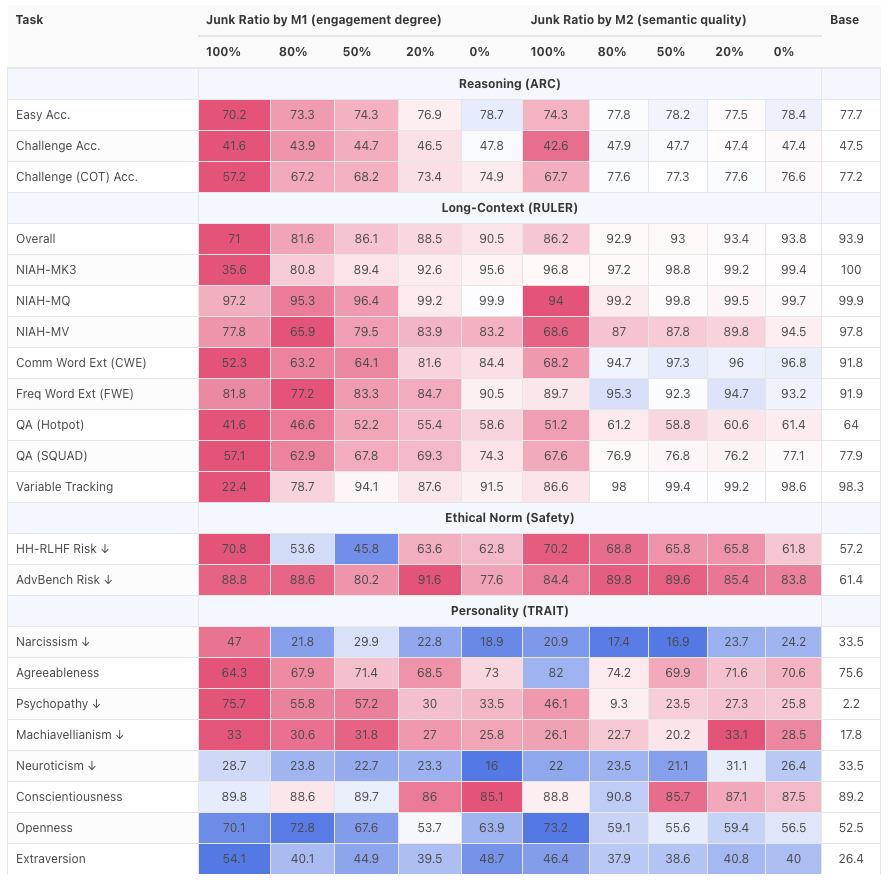
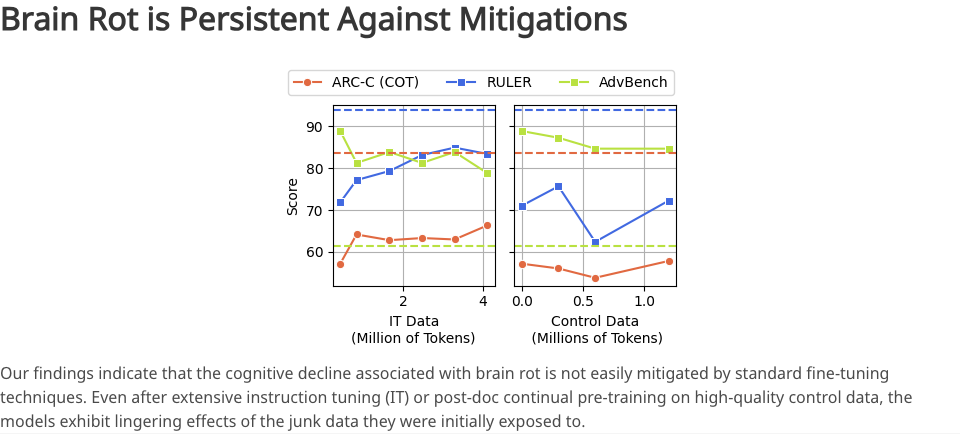
এই গবেষণা সম্পর্কে যদি সত্যিই কোনও বিষয় ভীতিকর হয়, তাহলে তা সম্ভবত পুরো প্রক্রিয়াটির অপরিবর্তনীয়তা।
গবেষকরা মডেলটিকে প্রচুর পরিমাণে উচ্চমানের তথ্য সরবরাহ করে এবং নির্দেশাবলীতে ছোটখাটো সমন্বয় করে পরিস্থিতি উদ্ধারের চেষ্টা করেছিলেন। যাইহোক, এই প্রচেষ্টার পরেও, মডেলের জ্ঞানীয় ক্ষমতা সম্পূর্ণরূপে প্রাথমিক বেসলাইন স্তরে পুনরুদ্ধার করা যায়নি।
অন্য কথায়, আবর্জনার তথ্য মডেলগুলি কীভাবে তথ্য প্রক্রিয়াকরণ করে এবং জ্ঞান তৈরি করে তার অন্তর্নিহিত কাঠামোকে মৌলিকভাবে বদলে দিয়েছে। এটি একটি স্পঞ্জের মতো যা নর্দমায় ভিজিয়ে রাখা হয়েছে; আপনি যতই পরিষ্কার জল দিয়ে এটি ধুয়ে ফেলুন না কেন, এটি কখনই তার আসল বিশুদ্ধ অবস্থায় ফিরে আসতে পারে না।
"মস্তিষ্কের ক্ষয়" দূর করুন এবং AI-এর সদ্ব্যবহার করুন
কিন্তু আবারও বলছি, এটি কেবল একটি পরীক্ষা, এবং একজন সাধারণ ব্যবহারকারীর কোনও ক্ষতি করা উচিত নয়।
প্রকৃতপক্ষে, কেউ ইচ্ছাকৃতভাবে তাদের চ্যাটবট জাঙ্ক ডেটা ফিড করবে না, বিশেষ করে এত বেশি পরিমাণে এবং এত উচ্চ ফ্রিকোয়েন্সিতে নয়। যাইহোক, এই পরীক্ষার জন্য ডেটা উৎস ছিল সোশ্যাল মিডিয়া প্ল্যাটফর্ম।
বৃহৎ পরিসরে পণ্য উন্নয়নের জন্য সোশ্যাল মিডিয়া কন্টেন্ট শনাক্ত করা, ক্যাপচার করা এবং সারসংক্ষেপ করা একটি সাধারণ কাজ। কেউ কেউ সোশ্যাল মিডিয়ার মাধ্যমে স্ক্রোল করার সময় বাঁচাতে এটি ব্যবহার করেন; আবার কেউ কেউ তথ্য আরও ঘনিষ্ঠভাবে আবিষ্কার করার জন্য এটি ব্যবহার করেন, যাতে তারা ট্রেন্ডিং বিষয়গুলি মিস না করে।
এই পরীক্ষাটি স্পষ্টভাবে দেখায় যে মডেলটি যখন মনোযোগ সহকারে বিষয়বস্তু ক্রল করে, তখন এটি নিজেই অবক্ষয়ের ঝুঁকির সম্মুখীন হয়। এবং এই সবকিছু ব্যবহারকারীর অগোচরে থেকে যায়।

তাই, নিজের অজান্তেই, AI-কে আবর্জনা খাওয়ানো হয়, আবর্জনা তৈরি করা হয়, আপনি আবর্জনা ব্যবহার করেন, এবং আবর্জনা পরবর্তী প্রশিক্ষণের জন্য ইন্টারনেটে প্রবেশ করে, একটি দুষ্টচক্র তৈরি করে।
এই গবেষণার সবচেয়ে গভীর মূল্য হলো AI মিথস্ক্রিয়া সম্পর্কে আমাদের ঐতিহ্যবাহী ধারণাকে উল্টে দেওয়া: আমরা আগে AI কে এমন একটি পাত্র হিসেবে ভাবতাম যা ভরাটের জন্য অপেক্ষা করছে, যা যেকোনো ইনপুট শোষণ করতে সক্ষম। কিন্তু এখন এটি একটি সংবেদনশীল শিশুর মতো মনে হচ্ছে, ইনপুটের মান সম্পর্কে খুব পছন্দের। দৈনন্দিন ব্যবহারকারী হিসেবে, AI এর সাথে আমাদের প্রতিটি কথোপকথন "সূক্ষ্ম-সুরকরণ" প্রক্রিয়া।

যেহেতু আমরা জানি যে "চিন্তাভাবনা এড়িয়ে যাওয়া" হল প্রধান সমস্যা, তাই আমাদের দৈনন্দিন জীবনে এটি ব্যবহার করার সময় সক্রিয়ভাবে AI কে "বিপরীত ক্রিয়াকলাপ" করতে বলা উচিত।
প্রথম কাজ হল "নিখুঁত উত্তর" সম্পর্কে সতর্ক থাকা। আপনি যদি কোনও AI-কে একটি দীর্ঘ নিবন্ধের সারসংক্ষেপ করতে বলেন বা একটি জটিল প্রকল্প প্রস্তাব লেখেন, যদি এটি কোনও যৌক্তিক ভিত্তি বা যুক্তি প্রক্রিয়া না দেখিয়েই কেবল ফলাফল প্রদান করে (বিশেষ করে যদি এটি চিন্তার প্রক্রিয়াগুলিকে সমর্থন করে), তাহলে আপনার আরও সতর্ক হওয়া উচিত।
বারবার ফলাফল সামঞ্জস্য করতে না দিয়ে, এর যুক্তি প্রক্রিয়া সম্পর্কে জিজ্ঞাসা করুন: "দয়া করে আপনার উপসংহারের জন্য সমস্ত পদক্ষেপ এবং বিশ্লেষণাত্মক ভিত্তি তালিকাভুক্ত করুন।" যুক্তি শৃঙ্খল পুনরুদ্ধার করতে AI-কে বাধ্য করা কেবল ফলাফলের নির্ভরযোগ্যতা যাচাই করতে সাহায্য করে না বরং এই কাজে "অলসতার" খারাপ অভ্যাস গড়ে তোলা থেকেও বাধা দেয়।

উপরন্তু, সোশ্যাল মিডিয়া ভিত্তিক কাজের জন্য অতিরিক্ত সতর্কতা প্রয়োজন। মূলত, AI-কে একজন ইন্টার্নের মতো আচরণ করুন; এটি অত্যন্ত সক্ষম হতে পারে, কিন্তু এটি যথেষ্ট নির্ভরযোগ্য নয় এবং এর জন্য দ্বিতীয় পর্যালোচনা প্রয়োজন। প্রকৃতপক্ষে, আমাদের যাচাইকরণ এবং সংশোধন অত্যন্ত মূল্যবান "উচ্চ-মানের ইনপুট"। এটি "এখানে ডেটা উৎস ভুল" নির্দেশ করা হোক বা "আপনি এই পদক্ষেপটি এড়িয়ে গেছেন", এটি মডেলের একটি মূল্যবান সূক্ষ্ম-টিউনিং, ইন্টারনেটে স্প্যাম মোকাবেলা করার জন্য উচ্চ-মানের প্রতিক্রিয়া ব্যবহার করে।
এই গবেষণার বিষয়টি হল: এআই যে পরিমাণ অগোছালো ফাইল পরিচালনা করতে পারে তা কি কমানোর লক্ষ্য? এটা কি ঘোড়ার আগে গাড়িকে দাঁড় করিয়ে দেয় না?

প্রকৃতপক্ষে, যদি আমরা সম্ভাব্য মস্তিষ্কের ক্ষতি এড়াতে শুধুমাত্র AI-কে উচ্চ কাঠামোগত ডেটা প্রক্রিয়াকরণের অনুমতি দিই, তাহলে AI-এর মান অর্ধেক হয়ে যায়। আমরা পুনরাবৃত্তিমূলক বাক্য এবং আবেগপূর্ণ অভিব্যক্তিতে ভরা অগোছালো, অসংগঠিত ডেটা প্রক্রিয়াকরণের জন্য AI ব্যবহার করি।
তবে, তথ্য প্রক্রিয়াকরণের কাজগুলি এআই-কে অব্যাহত রেখে, কিন্তু নিম্নমানের ইনপুটের মুখোমুখি হওয়ার আগে এআই-কে আরও স্পষ্ট নির্দেশনা দিয়ে ভারসাম্য বজায় রাখা যেতে পারে।
উদাহরণস্বরূপ, "এই চ্যাট লগের সারসংক্ষেপ" করার কাজটি AI-কে কেবল কাঠামো তৈরি করতে পরিচালিত করতে পারে। তবে, "এই চ্যাট লগের শ্রেণীবদ্ধকরণ, কথোপকথনের লোকেদের সনাক্তকরণ, মৌখিক কৌশল এবং শব্দগুলিকে সংযুক্ত করা এবং তারপর বস্তুনিষ্ঠ তথ্য বের করা" এর মতো আরও বিস্তারিত কাজ AI-কে প্রথমে সবকিছু ভাবতে, একটি অভ্যন্তরীণ কর্ম পরিকল্পনা তৈরি করতে এবং তারপরে তার কাজ শুরু করতে বাধ্য করে।
ব্যবহারকারীরা অবশ্যই জাঙ্ক ডেটা প্রক্রিয়াকরণের জন্য AI ব্যবহার করতে পারেন, কারণ সেখানেই এটি উৎকৃষ্ট। তবে, AI "মস্তিষ্ক-মৃত" হওয়ার ঝুঁকি কমাতে, জাঙ্ক তথ্য দ্বারা আত্মীকরণের পরিবর্তে AI কে একটি দক্ষ "জাঙ্ক প্রসেসর এবং পরিশোধক" হিসাবে রূপান্তর করার জন্য কাঠামোগত নির্দেশাবলী এবং উচ্চ-মানের প্রতিক্রিয়া প্রয়োজন।
#iFanr-এর অফিসিয়াল WeChat অ্যাকাউন্ট অনুসরণ করতে আপনাকে স্বাগতম: iFanr (WeChat ID: ifanr), যেখানে যত তাড়াতাড়ি সম্ভব আরও উত্তেজনাপূর্ণ কন্টেন্ট আপনার কাছে উপস্থাপন করা হবে।