

ওপেন-সোর্স মডেলটি আরেকটি শক্তিশালী প্রতিযোগীকে স্বাগত জানিয়েছে। সম্প্রতি, Xiaomi আনুষ্ঠানিকভাবে তাদের নতুন মডেল, MiMo-V2-Flash, প্রকাশ করেছে এবং ওপেন-সোর্স করেছে।
MiMo-V2-Flash-এর মোট ৩০৯ বিলিয়ন প্যারামিটার রয়েছে, যার মধ্যে ১৫ বিলিয়ন সক্রিয় প্যারামিটার রয়েছে। এটি একটি হাইব্রিড এক্সপার্ট আর্কিটেকচার (MoE) গ্রহণ করে এবং এর কর্মক্ষমতা DeepSeek-V3.2 এবং Kimi-K2-এর মতো শীর্ষস্থানীয় ওপেন-সোর্স মডেলগুলির সাথে প্রতিযোগিতা করতে পারে।

এছাড়াও, MiMo-V2-Flash MIT ওপেন সোর্স লাইসেন্স গ্রহণ করে এবং এর মৌলিক কপিরাইট Hugging Face-এও প্রকাশিত হয়েছে। ওপেন সোর্স হওয়ার পাশাপাশি, নতুন মডেলের আসল বৈশিষ্ট্য হল স্থাপত্য নকশায় এর আমূল উদ্ভাবন, যা অনুমানের গতিকে ১৫০ টোকেন/সেকেন্ডে উন্নীত করেছে এবং খরচ প্রতি মিলিয়ন টোকেন ইনপুট $0.1 এবং প্রতি মিলিয়ন আউটপুট $0.3 এ কমিয়েছে, যা এটিকে একটি অসাধারণ খরচ-কর্মক্ষমতা অনুপাত করে তুলেছে।
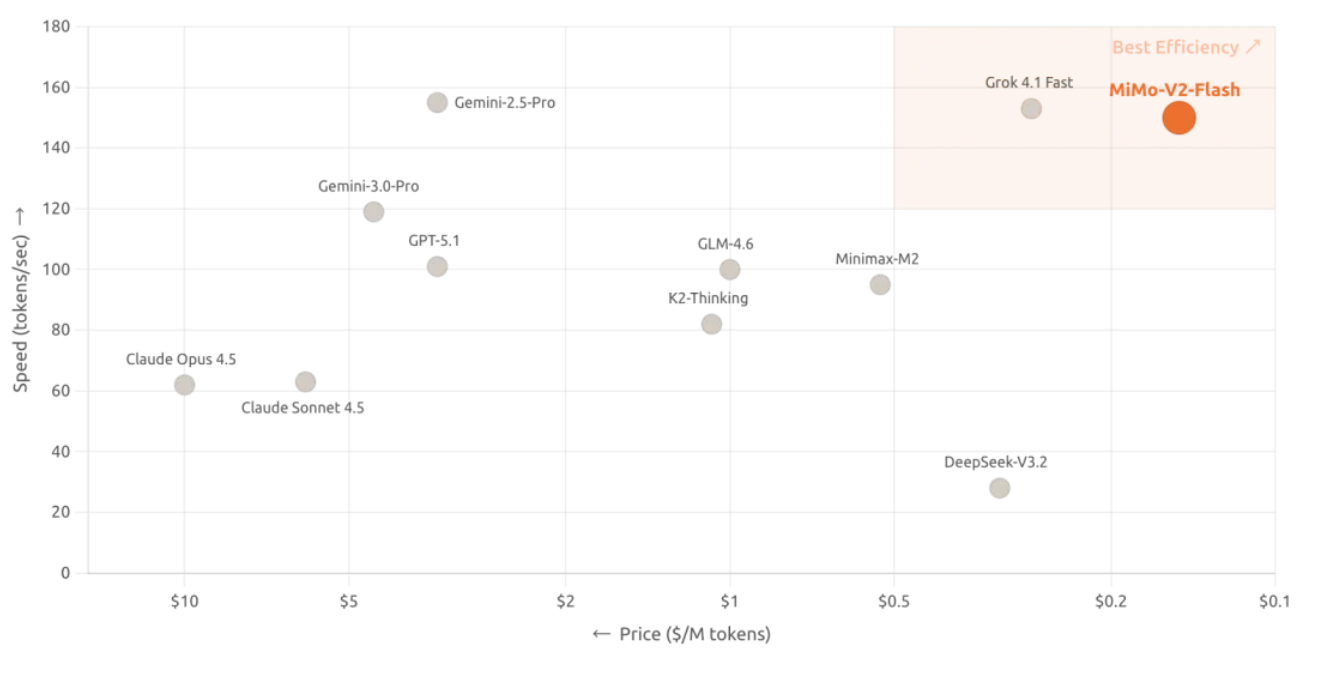
অফিসিয়াল পেজ অনুযায়ী, MiMo-V2-Flash গভীর চিন্তাভাবনা এবং অনলাইন অনুসন্ধান ফাংশন সমর্থন করে, যার অর্থ এটি কেবল কোড লিখতে এবং গণিত সমস্যা সমাধান করতে পারে না, বরং রিয়েল টাইমে সর্বশেষ তথ্যও পেতে পারে।
এআই স্টুডিও অভিজ্ঞতার লিঙ্ক এখানে:
http://aistudio.xiaomimimo.com
SWE-Bench ওপেন-সোর্স মডেলের জন্য একটি নতুন মানদণ্ড স্থাপন করেছে, ওপেন-সোর্স চার্টের শীর্ষে।
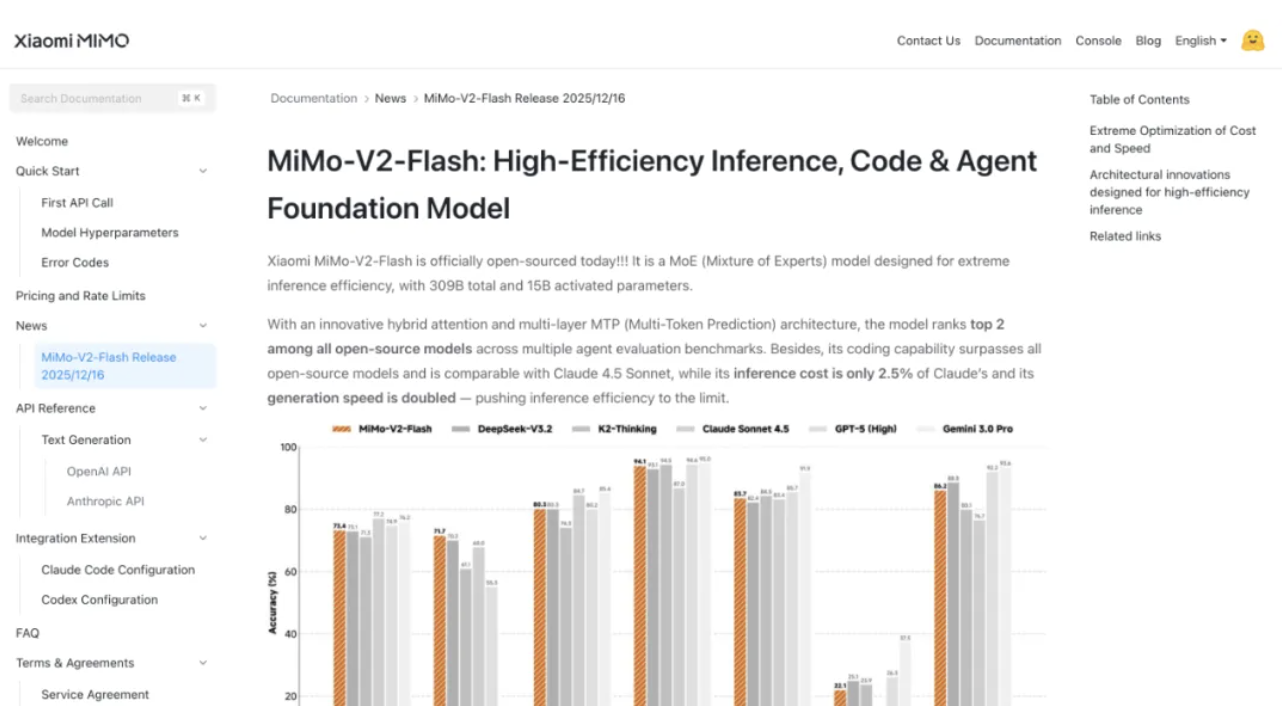
যথারীতি, প্রথমে MiMo-V2-Flash এর বেঞ্চমার্ক স্কোরগুলি দেখে নেওয়া যাক।
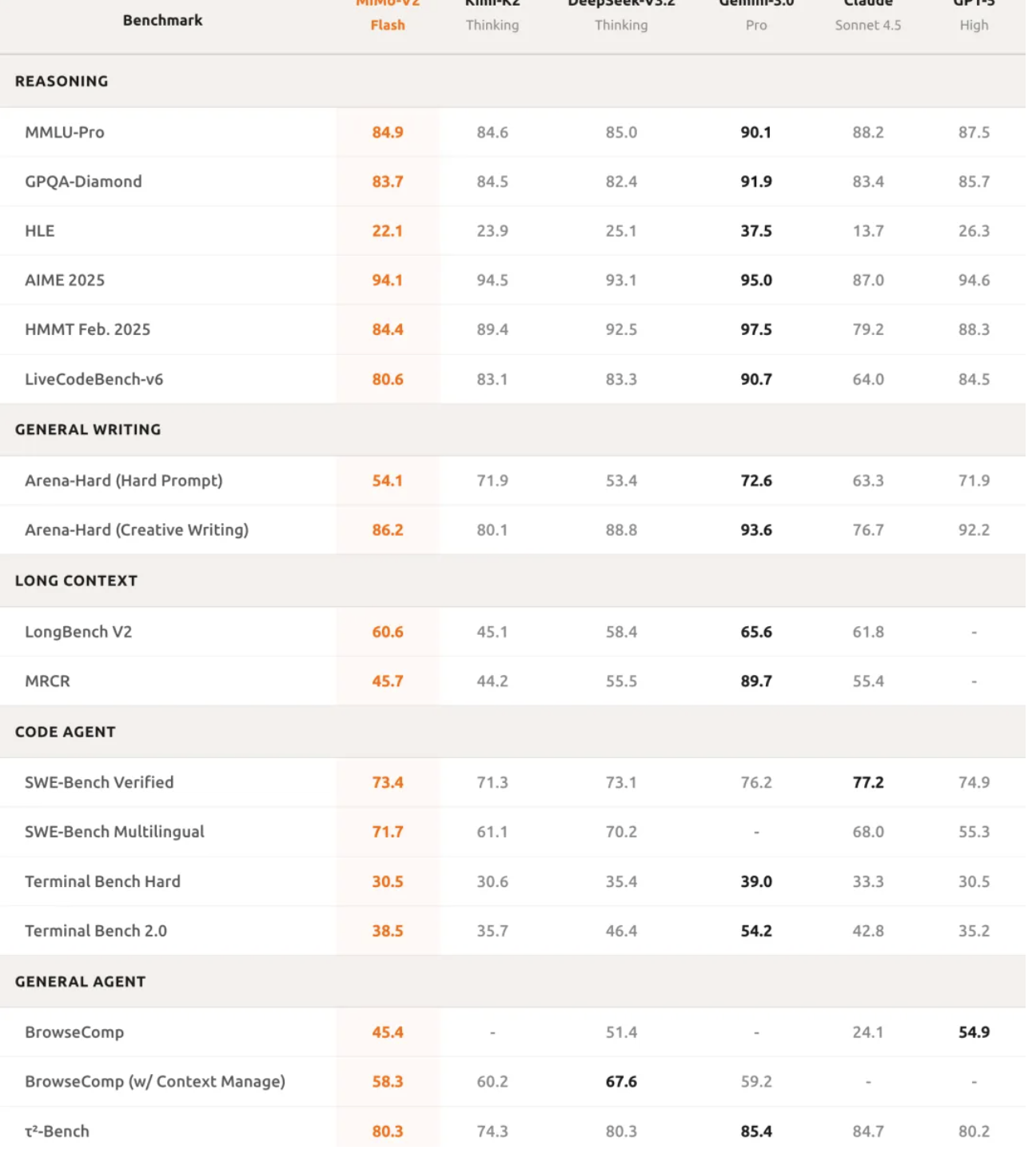
গাণিতিক যুক্তিতে, AIME 2025 গণিত প্রতিযোগিতা এবং GPQA-ডায়মন্ড সায়েন্স নলেজ টেস্ট উভয় ক্ষেত্রেই MiMo-V2-Flash শীর্ষ দুটি ওপেন-সোর্স মডেলের মধ্যে স্থান পেয়েছে।
এর প্রোগ্রামিং ক্ষমতা আরও চিত্তাকর্ষক, SWE-বেঞ্চ যাচাইকৃত পরীক্ষায় 73.4% স্কোর করেছে, সমস্ত ওপেন-সোর্স মডেলকে ছাড়িয়ে গেছে এবং GPT-5-High-এর কাছাকাছি পৌঁছেছে। সহজভাবে বলতে গেলে, এই পরীক্ষাটি AI-কে বাস্তব-বিশ্বের সফ্টওয়্যার বাগগুলির মুখোমুখি করে, এবং 73.4% সাফল্যের হারের অর্থ হল এটি বেশিরভাগ ব্যবহারিক প্রোগ্রামিং সমস্যাগুলি পরিচালনা করতে পারে।
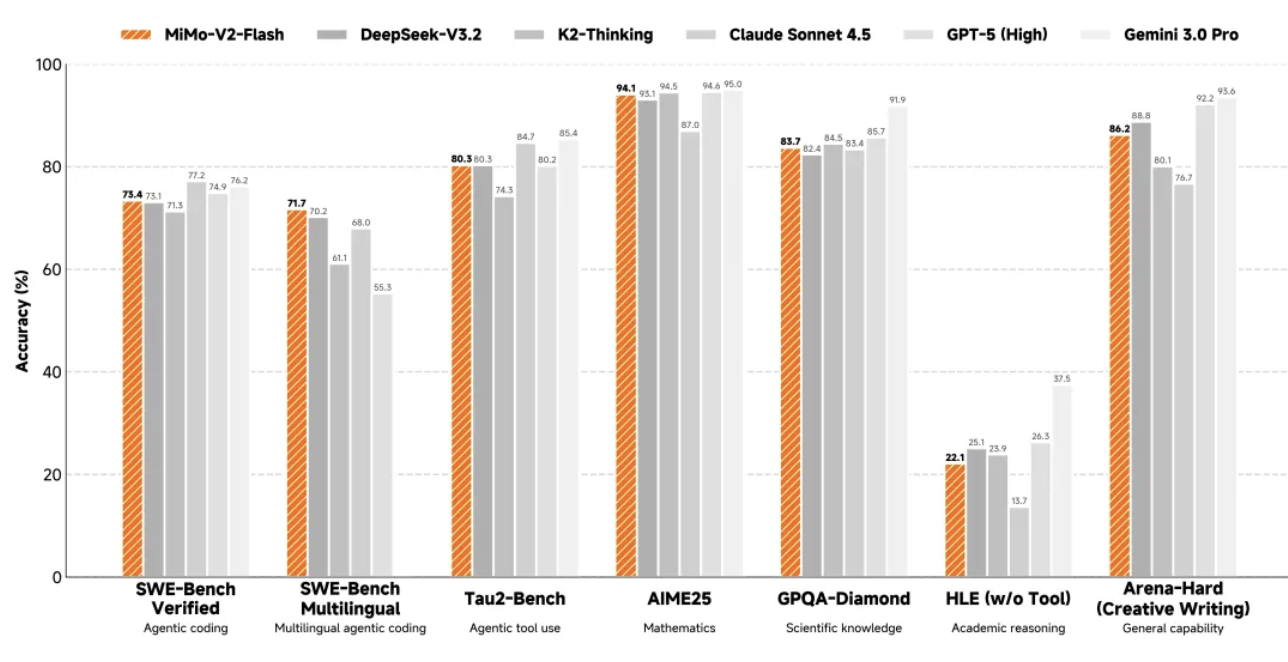
SWE-Bench বহুভাষিক বেঞ্চমার্ক পরীক্ষায়, রেজোলিউশন রেট ছিল 71.7%। ইন্টেলিজেন্ট এজেন্ট টাস্কে, MiMo-V2-Flash τ²-Bench শ্রেণীবিভাগ পরীক্ষায় যোগাযোগ বিভাগে 95.3 পয়েন্ট, খুচরা বিভাগে 79.5 পয়েন্ট এবং বিমান বিভাগে 66.0 পয়েন্ট পেয়েছে।
ব্রাউজকম্পের সার্চ এজেন্ট স্কোর ছিল ৪৫.৪, কিন্তু কনটেক্সট ম্যানেজমেন্ট সক্ষম করার পর তা ৫৮.৩-এ উন্নীত হয়েছে।
এই তথ্যগুলি প্রমাণ করে যে MiMo-V2-Flash কেবল কোড লিখতে পারে না, বরং জটিল টাস্ক লজিকও বুঝতে পারে এবং মাল্টি-টার্ন এজেন্ট ইন্টারঅ্যাকশনগুলি কার্যকর করতে পারে। এর দীর্ঘ টেক্সট প্রক্রিয়াকরণ ক্ষমতাও চিত্তাকর্ষক; বাস্তব-বিশ্বের পরীক্ষায়, এর কর্মক্ষমতা এমনকি বৃহত্তর Kimi-K2 Thinking-কে ছাড়িয়ে যায়, যা হাইব্রিড স্লাইডিং উইন্ডো অ্যাটেনশন আর্কিটেকচারের শক্তিশালী দীর্ঘ-পরিসরের মডেলিং ক্ষমতা প্রমাণ করে।
লেখার মানও শীর্ষ-স্তরের ক্লোজড-সোর্স মডেলগুলির কাছাকাছি, যার অর্থ হল MiMo-V2-Flash কেবল একটি হাতিয়ার নয়, বরং একটি নির্ভরযোগ্য দৈনিক সহকারীও।
দীর্ঘ টেক্সট আউটপুটের জন্য কর্মক্ষমতা বজায় রাখা এবং খরচ ৬ গুণ কমানোর রহস্য।
MiMo-V2-Flash এর মূল উদ্ভাবন হল এর হাইব্রিড স্লাইডিং উইন্ডো অ্যাটেনশন মেকানিজম।
যখন ঐতিহ্যবাহী বৃহৎ-স্কেল মডেলগুলি দীর্ঘ টেক্সট প্রক্রিয়া করে, তখন বিশ্বব্যাপী মনোযোগ প্রক্রিয়া গণনার লোডে একটি গৌণ বিস্ফোরণ ঘটায় এবং মধ্যবর্তী ফলাফল সংরক্ষণের জন্য কী-মান ক্যাশেও আকাশচুম্বী হয়। Xiaomi এবার একটি আক্রমণাত্মক 5:1 অনুপাত গ্রহণ করেছে, স্লাইডিং উইন্ডো মনোযোগের 5 স্তর এবং বিশ্বব্যাপী মনোযোগের 1 স্তরের মধ্যে পর্যায়ক্রমে, স্লাইডিং উইন্ডোতে কেবল 128 টোকেন বিবেচনা করা হয়েছে।
(যারা AI এর সাথে অপরিচিত তাদের জন্য, এখানে একটি সংক্ষিপ্ত ব্যাখ্যা দেওয়া হল: বৃহৎ-স্কেল মডেলিং/প্রাকৃতিক ভাষা প্রক্রিয়াকরণে, একটি "টোকেন" বলতে টেক্সট পড়ার এবং আউটপুট করার সময় মডেল দ্বারা ব্যবহৃত ক্ষুদ্রতম গণনা ইউনিটকে বোঝায়। মডেলটি "একটি চীনা অক্ষর = 1, একটি ইংরেজি শব্দ = 1" এর মতো নির্দিষ্ট পদ্ধতিতে গণনা করে না, বরং টেক্সটটিকে টোকেনের অংশে ভাগ করে প্রক্রিয়া করে।)
সহজ কথায়, মডেলটিকে প্রতিবার সমস্ত কন্টেন্ট দেখার প্রয়োজন হয় না; এটি শুধুমাত্র সাম্প্রতিকতম ১২৮টি টোকেন দেখে এবং মাঝে মাঝে বিশ্বব্যাপী তালিকা পরীক্ষা করে। এটি উল্লেখযোগ্যভাবে গণনা এবং স্টোরেজ প্রয়োজনীয়তা হ্রাস করে। এই নকশাটি KV ক্যাশে স্টোরেজ প্রায় ৬ গুণ কমিয়ে দেয়, তবে দীর্ঘ টেক্সট ক্ষমতার সাথে আপস করে না, সর্বোচ্চ ২৫৬k কনটেক্সট উইন্ডো সমর্থন করে।
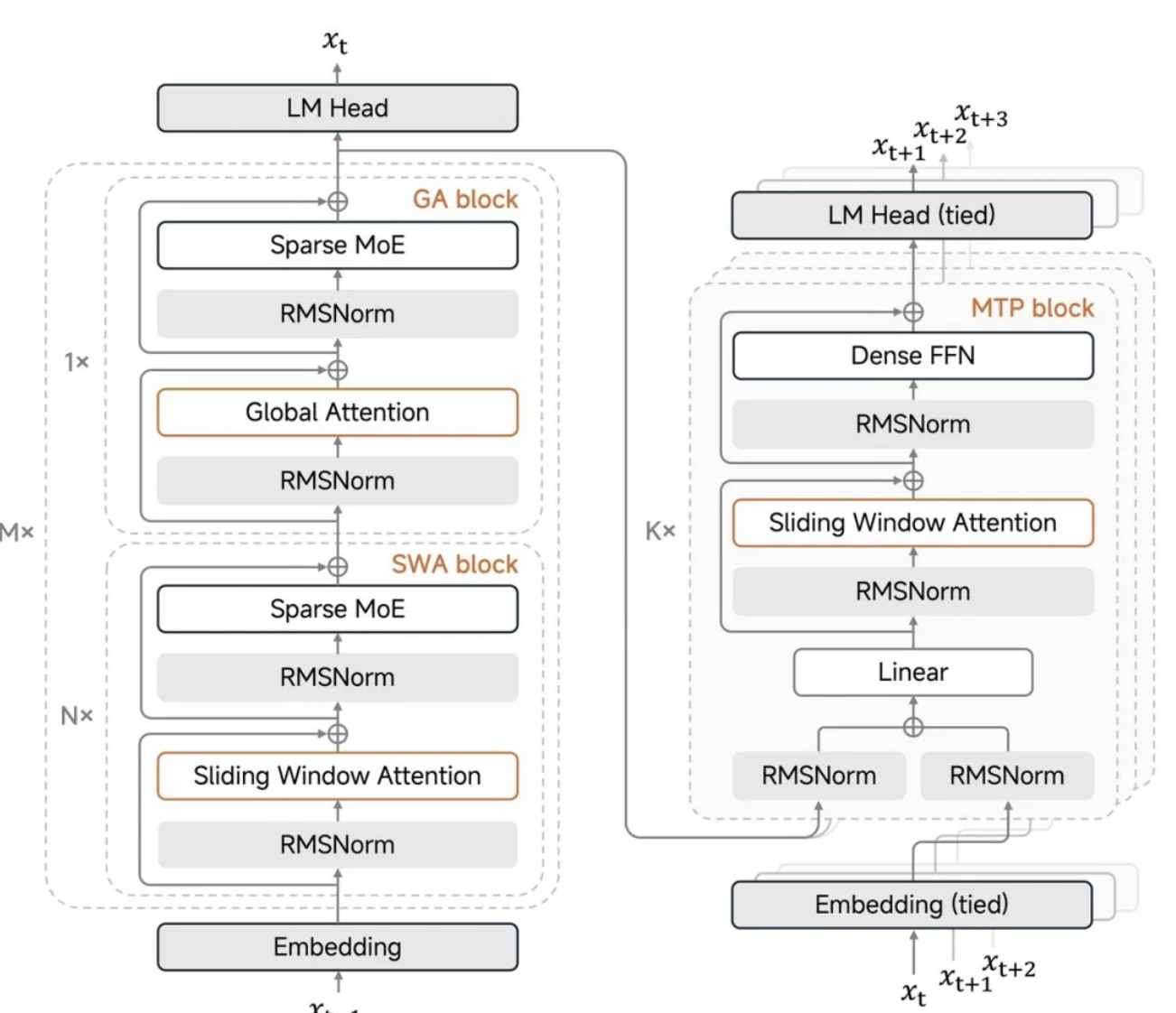
মূল বিষয় হলো, শাওমি "শিখতে পাওয়া যায় এমন মনোযোগ প্রবাহ পক্ষপাত" তৈরি করেছে, যা মডেলটিকে এত আক্রমণাত্মক উইন্ডো সেটিংসের মধ্যেও দীর্ঘ টেক্সটের জন্য স্থিতিশীল কর্মক্ষমতা বজায় রাখতে সাহায্য করে।
লুও ফুলি সোশ্যাল মিডিয়ায় জোর দিয়ে বলেছেন যে ১২৮ এর উইন্ডো সাইজ "সর্বোত্তম মান" হিসেবে প্রমাণিত হয়েছে, যেখানে ৫১২ আসলে কর্মক্ষমতা হ্রাসের দিকে পরিচালিত করে। এই আবিষ্কারটি বেশ বিপরীতমুখী; আপনি হয়তো ভাবতে পারেন যে উইন্ডো যত বড় হবে তত ভালো, কিন্তু প্রকৃত পরীক্ষায়, ১২৮ হল মিষ্টি জায়গা। অতিরিক্তভাবে, সিঙ্ক মান (মনোযোগ সিঙ্ক মান) অপরিহার্য এবং কখনই বাদ দেওয়া উচিত নয়।
আরেকটি অত্যাধুনিক প্রযুক্তি হল লাইটওয়েট মাল্টি-টোকেন প্রেডিকশন (MTP)।
ঐতিহ্যবাহী মডেলগুলি টেক্সট তৈরি করার সময় একবারে কেবল একটি টোকেন আউটপুট করতে পারে, অনেকটা টাইপিস্টের মতো, যা একবারে একটি শব্দ টাইপ করে। MiMo-V2-Flash, তার স্থানীয়ভাবে সমন্বিত MTP মডিউলের মাধ্যমে, সমান্তরালভাবে একাধিক টোকেন অনুমান করতে পারে, একসাথে বেশ কয়েকটি টোকেন অনুমান করতে পারে।
প্রকৃত পরীক্ষায়, এটি গড়ে ২.৮ থেকে ৩.৬ টোকেন গ্রহণ করতে পারে, যা সরাসরি অনুমানের গতি ২ থেকে ২.৬ গুণ বৃদ্ধি করে। এটি কেবল অনুমানের সময়ই কার্যকর নয়, বরং নমুনা গ্রহণকে ত্বরান্বিত করে এবং প্রশিক্ষণ পর্যায়ে GPU নিষ্ক্রিয় সময় হ্রাস করে, যা দ্বিগুণ সুবিধা।
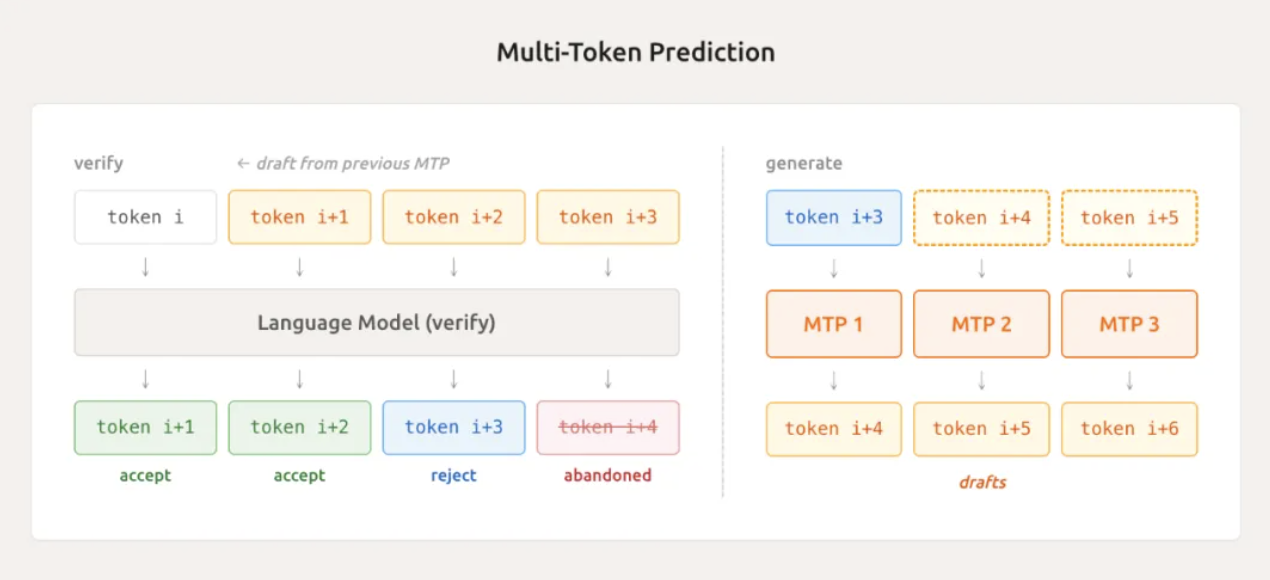
লুও ফুলি উল্লেখ করেছেন যে তিন-স্তরের MTP সেটআপের মাধ্যমে, তারা গড়ে ৩-এর বেশি গ্রহণযোগ্যতা দৈর্ঘ্য লক্ষ্য করেছেন, যার ফলে এনকোডিং টাস্কের জন্য প্রায় ২.৫ গুণ গতি বৃদ্ধি পেয়েছে। এটি মিনি-ব্যাচ অন-পলিসি রিইনফোর্সমেন্ট লার্নিংয়ে "লং-টেইল্ড স্যাম্পল" এর কারণে GPU নিষ্ক্রিয় সময়ের অপচয়কে কার্যকরভাবে সমাধান করে।
লং-টেইলড স্যাম্পল কী? এগুলি হল বিশেষ করে কঠিন এবং ধীরগতির কাজ যা অন্যান্য কাজগুলিকেও তাদের সাথে টেনে নিয়ে যায়, যার ফলে GPU আটকে যায়। MTP এই সমস্যার সমাধান করে, দক্ষতা নাটকীয়ভাবে উন্নত করে।
তবে, লুও ফুলি স্বীকার করেছেন যে সময়ের সীমাবদ্ধতার কারণে, তারা এবার আরএল প্রশিক্ষণ লুপে এমটিপি সম্পূর্ণরূপে সংহত করতে পারেনি, তবে এটি প্রক্রিয়াটির সাথে অত্যন্ত সামঞ্জস্যপূর্ণ। শাওমি ইতিমধ্যেই তিন-স্তরের এমটিপি ওপেন-সোর্স করেছে, যা প্রত্যেকের জন্য তাদের নিজস্ব প্রকল্পে ব্যবহার এবং বিকাশের সুবিধাজনক করে তুলেছে।
যখন কম্পিউটিং শক্তির মাত্র ১/৫০ ভাগ ব্যবহার করা হয়, তখন কর্মক্ষমতা কীভাবে ক্ষতিগ্রস্ত হবে না?
প্রাক-প্রশিক্ষণ পর্যায়ে, নতুন মডেলটি FP8 মিশ্র নির্ভুলতা ব্যবহার করে এবং 27 ট্রিলিয়ন টোকেন ডেটার উপর প্রশিক্ষিত হয়, যা স্থানীয়ভাবে 32k এর সিকোয়েন্স দৈর্ঘ্যকে সমর্থন করে।
FP8 মিশ্র নির্ভুলতা হল সংখ্যাসূচক উপস্থাপনা সংকুচিত করার একটি কৌশল, যা মেমরির ব্যবহার কমাতে পারে এবং নির্ভুলতা বজায় রেখে প্রশিক্ষণকে ত্বরান্বিত করতে পারে। এই প্রশিক্ষণ পদ্ধতিটি শিল্পে সাধারণ নয় এবং এর জন্য অন্তর্নিহিত কাঠামোর গভীর অপ্টিমাইজেশন প্রয়োজন।
পরবর্তী প্রশিক্ষণ পর্বে, Xiaomi মাল্টি-টিচার অনলাইন স্ট্র্যাটেজি ডিস্টিলেশন (MOPD) প্রস্তাব করে একটি বড় উদ্ভাবন এনেছে।
ঐতিহ্যবাহী তত্ত্বাবধানে থাকা সূক্ষ্ম-সুরকরণ শক্তিবৃদ্ধি শেখার পাইপলাইনগুলি কেবল প্রশিক্ষণের ক্ষেত্রেই অস্থির নয় বরং গণনার দিক থেকেও অত্যন্ত ব্যয়বহুল। MOPD পদ্ধতির মধ্যে রয়েছে শিক্ষার্থীর মডেল নমুনাকে নিজস্ব নীতি বিতরণে রাখা, এবং তারপরে একাধিক বিশেষজ্ঞ শিক্ষককে প্রতিটি টোকেন অবস্থানে ঘন পুরষ্কার সংকেত প্রদান করা।
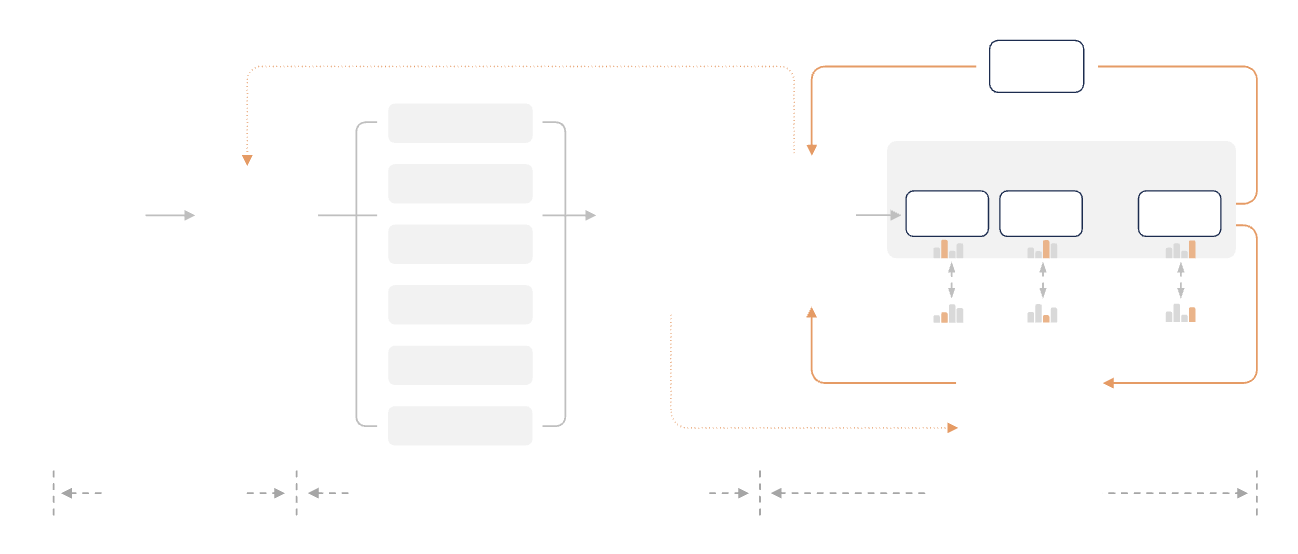
সহজ ভাষায় বলতে গেলে, শিক্ষার্থী মডেল স্বাধীনভাবে হোমওয়ার্ক করে এবং শিক্ষক সম্পূর্ণ লেখার জন্য অপেক্ষা না করেই প্রতিটি শব্দকে পৃথকভাবে গ্রেড করেন। এটি শিক্ষার্থী মডেলকে শিক্ষকের কাছ থেকে প্রয়োজনীয় জিনিসগুলি দ্রুত শিখতে সাহায্য করে এবং প্রশিক্ষণ প্রক্রিয়া অনেক বেশি স্থিতিশীল হয়।
সবচেয়ে উল্লেখযোগ্য উন্নতি হল দক্ষতার ক্ষেত্রে। শিক্ষক মডেলের তুলনায় শিক্ষার্থী মডেলের সর্বোচ্চ কর্মক্ষমতা অর্জনের জন্য MOPD-এর প্রথাগত পদ্ধতির কম্পিউটিং শক্তির মাত্র 1/50 ভাগের এক ভাগ প্রয়োজন। এর অর্থ হল Xiaomi কম রিসোর্সে দ্রুত মডেলগুলিতে পুনরাবৃত্তি করতে পারে।
অধিকন্তু, MOPD নতুন শিক্ষকদের নমনীয় একীকরণকে সমর্থন করে, এবং শিক্ষার্থী মডেলরা বড় হওয়ার পরে নিজেরাই শিক্ষক হতে পারে, "শিক্ষাদান এবং শেখার" একটি বন্ধ-লুপ স্ব-বিবর্তন তৈরি করে। আজকের শিক্ষার্থীরা আগামীকালের শিক্ষক হতে পারে, এবং পরশু তারা আরও শক্তিশালী শিক্ষার্থী তৈরি করতে পারে। এই নেস্টেড পুতুলের মতো পদ্ধতিটি সত্যিই উদ্ভাবনী।
লুও ফুলির ভাষায়, তারা একাধিক রিইনফোর্সমেন্ট লার্নিং মডেলগুলিকে একত্রিত করার জন্য থিঙ্কিং মেশিন থেকে অন-পলিসি ডিস্টিলেশন পদ্ধতি ধার করেছিল, যার ফলে দক্ষতায় উল্লেখযোগ্য উন্নতি হয়েছিল। এটি একটি স্ব-রিইনফোর্সিং লুপ সিস্টেম তৈরির ভিত্তি স্থাপন করেছিল যেখানে শিক্ষার্থী মডেলগুলি ধীরে ধীরে শক্তিশালী শিক্ষক মডেলে বিকশিত হতে পারে।
এজেন্ট রিইনফোর্সমেন্ট লার্নিং এক্সটেনশনের ক্ষেত্রে, Xiaomi MiMo-V2-Flash গবেষণা দল বাস্তব GitHub সমস্যাগুলির উপর ভিত্তি করে 100,000 টিরও বেশি যাচাইযোগ্য কাজ তৈরি করেছে। স্বয়ংক্রিয় পাইপলাইনটি একটি Kubernetes ক্লাস্টারে চলে, যা 70% পরিবেশগত স্থাপনার সাফল্যের হার সহ একসাথে 10,000 টিরও বেশি পড চালাতে সক্ষম।
ওয়েব ডেভেলপমেন্ট কাজের জন্য, একটি মাল্টিমোডাল ভ্যালিডেটরও তৈরি করা হয়েছিল। এটি স্ট্যাটিক স্ক্রিনশটের পরিবর্তে ভিডিও রেকর্ড করে কোড এক্সিকিউশনের ফলাফল যাচাই করে, সরাসরি ভিজ্যুয়াল ইলিউশন কমায় এবং ফাংশনগুলি সঠিক কিনা তা নিশ্চিত করে।
ডেভেলপারদের জন্য, MiMo-V2-Flash ক্লড কোড, কার্সার এবং ক্লাইনের মতো মূলধারার ডেভেলপমেন্ট পরিবেশের সাথে নির্বিঘ্নে একীভূত হতে পারে এবং এর অতি-দীর্ঘ 256k কনটেক্সট উইন্ডো শত শত রাউন্ড এজেন্ট ইন্টারঅ্যাকশন এবং টুল কল সমর্থন করে।
২৫৬ কে বলতে কী বোঝায়? এটি মোটামুটি একটি মাঝারি দৈর্ঘ্যের উপন্যাস বা কয়েক ডজন পৃষ্ঠার প্রযুক্তিগত ডকুমেন্টেশনের সমতুল্য। এর অর্থ হল ডেভেলপাররা কোনও অতিরিক্ত অভিযোজন ছাড়াই তাদের বিদ্যমান কর্মপ্রবাহে MiMo-V2-Flash সরাসরি সংহত করতে পারে; তারা এটিকে সরাসরি বাক্সের বাইরে ব্যবহার করতে পারে।
Xiaomi তার সমস্ত ইনফারেন্স কোড SGLang-এ অবদান রেখেছে এবং LMSYS ব্লগে তার ইনফারেন্স অপ্টিমাইজেশন অভিজ্ঞতা শেয়ার করেছে।
কারিগরি প্রতিবেদনে মডেলের সম্পূর্ণ বিবরণ প্রকাশ করা হয়েছে এবং মডেলের ওজন (MiMo-V2-Flash-Base সহ) MIT লাইসেন্সের অধীনে Hugging Face-এ প্রকাশিত হয়েছে। এই ব্যাপক ওপেন-সোর্স পদ্ধতিটি প্রধান চীনা কোম্পানিগুলির মধ্যে সত্যিই বিরল।
MiMo-V2-Flash বর্তমানে সীমিত সময়ের জন্য API প্ল্যাটফর্মে বিনামূল্যে পাওয়া যাচ্ছে, যা ডেভেলপারদের তাৎক্ষণিকভাবে শুরু করার সুযোগ করে দেবে।
Xiaomi-এর AI উচ্চাকাঙ্ক্ষা কেবল একটি মোবাইল সহকারীর বাইরেও বিস্তৃত।
MiMo-V2-Flash এর মুক্তি AI ক্ষেত্রে Xiaomi-এর পূর্ণাঙ্গ প্রচেষ্টার প্রতীক।
লুও ফুলি সোশ্যাল মিডিয়ায় আরও তথ্য প্রকাশ করেছেন, "MiMo-V2-Flash আনুষ্ঠানিকভাবে চালু হয়েছে। এটি আমাদের AGI রোডম্যাপের মাত্র দ্বিতীয় ধাপ।" দ্বিতীয় ধাপটি ইতিমধ্যেই এত চিত্তাকর্ষক, তাহলে আর কী বড় চমক অপেক্ষা করছে? এটি এমন কিছু যা দেখার অপেক্ষায় রয়েছে।
অবশ্যই, Xiaomi তাদের টেকনিক্যাল রিপোর্টে অকপটে স্বীকার করেছে যে MiMo-V2-Flash এখনও সবচেয়ে শক্তিশালী ক্লোজড-সোর্স মডেলগুলির থেকে পিছিয়ে রয়েছে। তবে, তাদের পরিকল্পনা স্পষ্ট: মডেলের আকার বৃদ্ধি এবং কম্পিউটিং শক্তি প্রশিক্ষণের মাধ্যমে ব্যবধান কমানো, একই সাথে আরও শক্তিশালী এবং দক্ষ এজেন্ট আর্কিটেকচার অন্বেষণ চালিয়ে যাওয়া।
এমওপিডি কাঠামোর অধীনে শিক্ষক এবং শিক্ষার্থী মডেলগুলির পুনরাবৃত্তিমূলক সহ-বিবর্তন ভবিষ্যতের সক্ষমতা বৃদ্ধির জন্য যথেষ্ট জায়গা রাখে।
বৃহত্তর দৃষ্টিকোণ থেকে দেখলে, এটি সমগ্র AI ইকোসিস্টেমের উপর Xiaomi-এর একটি কৌশলগত বাজি। স্মার্টফোন এবং IoT থেকে শুরু করে অটোমোবাইল পর্যন্ত, Xiaomi-এর হার্ডওয়্যার ইকোসিস্টেমের একটি শক্তিশালী AI ভিত্তি প্রয়োজন, এবং MiMo-V2-Flash স্পষ্টতই ভিত্তিপ্রস্তর যা Xiaomi তার সমগ্র হার্ডওয়্যার ইকোসিস্টেমের জন্য প্রস্তুতি নিচ্ছে।
এক দশক আগে Xiaomi যেমন ১৯৯৯ ইউয়ান মূল্যের ফোন দিয়ে ফ্ল্যাগশিপ ফোনের দামের মান পুনর্নির্ধারণ করেছিল, ঠিক তেমনই MiMo-V2-Flash এখন ওপেন-সোর্স বৃহৎ মডেলের জন্য পারফরম্যান্স মান পুনর্নির্ধারণ করছে, যার দাম প্রতি মিলিয়ন টোকেন $0.1 এবং SWE-Bench স্কোর ৭৩.৪%।
এবার, ওপেন সোর্স মডেলের "শাওমি মুহূর্ত" সত্যিই এসে গেছে।
HuggingFace মডেল ঠিকানা:
http://hf.co/XiaomiMiMo/MiMo-V2-Flash
কারিগরি প্রতিবেদনের ঠিকানা:
http://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf
#iFanr-এর অফিসিয়াল WeChat অ্যাকাউন্ট অনুসরণ করতে আপনাকে স্বাগতম: iFanr (WeChat ID: ifanr), যেখানে যত তাড়াতাড়ি সম্ভব আরও উত্তেজনাপূর্ণ কন্টেন্ট আপনার কাছে উপস্থাপন করা হবে।