

১১০৬ দিনের মধ্যে, ওপেনএআই টেবিল উল্টে দেওয়ার কারিগর থেকে টেবিল উল্টে দেওয়ার কারিগরে পরিণত হয়।
গুগল জেমিনি ৩ প্রকাশের সাথে সাথে, ওপেনএআই-এর সিইও অল্টম্যান গত সপ্তাহে একটি বিরল "কোড রেড" সতর্কতা জারি করেছিলেন, ঘোষণা করেছিলেন যে সমস্ত সংস্থান চ্যাটজিপিটি মূল লাইনে ফিরিয়ে দেওয়া হবে এবং অন্যান্য ব্যবসাগুলিকে সাইডলাইন করা হবে।
ওপেনএআই প্রতিষ্ঠার পর থেকে এটি প্রথমবারের মতো "রেড অ্যালার্ট" অবস্থায় প্রবেশ করেছে, এবং এটি প্রথমবারের মতো এটি এত স্পষ্টভাবে স্বীকার করেছে যে প্রতিযোগিতামূলক চাপ এত বেশি হয়ে গেছে যে এটিকে তার সর্বশক্তি দিয়ে এটি মোকাবেলা করতে হবে।

এইমাত্র, OpenAI GPT-5.2 মডেলটি প্রকাশ করেছে, যা একটি শক্তিশালী ধাক্কা দিয়েছে। GPT-5.2 API এর মাধ্যমে ChatGPT অর্থপ্রদানকারী ব্যবহারকারী এবং ডেভেলপারদের জন্য উপলব্ধ হবে এবং তিনটি সংস্করণে প্রকাশিত হবে:
- তাৎক্ষণিক: তথ্য পুনরুদ্ধার, লেখা এবং অনুবাদের মতো নিয়মিত কাজের জন্য উপযুক্ত একটি গতি-অপ্টিমাইজড সংস্করণ;
- চিন্তাভাবনা: জটিল কাঠামোগত কাজ পরিচালনায় দক্ষ, যেমন প্রোগ্রামিং, দীর্ঘ নথি বিশ্লেষণ, গণিত এবং পরিকল্পনা;
- প্রো: উচ্চমানের সংস্করণ, চ্যালেঞ্জিং কাজের জন্য চূড়ান্ত নির্ভুলতা এবং নির্ভরযোগ্যতা প্রদানের উপর দৃষ্টি নিবদ্ধ করে।
কোন আড্ডা নয়, শুধু আসল কাজ: GPT-5.2 কর্মরত পেশাদারদের কর্মক্ষেত্রে প্রবেশ করেছে।
মনে করা হয়েছিল যে OpenAI ChatGPT-এর ব্যক্তিগতকরণ এবং ভোক্তা অভিজ্ঞতা উন্নত করার উপর মনোনিবেশ করবে, কিন্তু GPT-5.2-এর প্রকাশ এখনও কর্মক্ষেত্রের বাস্তববাদের পথ অনুসরণ করে।
ওপেনএআই-এর সিইও ফিদজি সিমোর ভাষায়, "আমরা ব্যবহারকারীদের জন্য আরও অর্থনৈতিক মূল্য তৈরি করার জন্য GPT-5.2 ডিজাইন করেছি।"
অর্থনৈতিক মূল্য কী?
লক্ষ্য হল AI-কে স্প্রেডশিট তৈরি, পাওয়ারপয়েন্ট প্রেজেন্টেশন লেখা, কোডিং, ছবি দেখা, দীর্ঘ নিবন্ধ পড়া, টুল কল করা এবং জটিল প্রকল্প পরিচালনা করার মতো কাজগুলি বাস্তবে করতে সক্ষম করা – এই সবই GPT-5.2-এর শক্তি।
তথ্যটি বেশ চিত্তাকর্ষক। গড়ে, প্রতিটি ChatGPT এন্টারপ্রাইজ ব্যবহারকারী বলেছেন যে AI তাদের প্রতিদিন 40 থেকে 60 মিনিট সাশ্রয় করে, এবং ভারী ব্যবহারকারীরা আরও বেশি সাশ্রয় করে, প্রতি সপ্তাহে 10 ঘন্টারও বেশি।

GPT-5.2 চিন্তাভাবনা এই রিলিজের হাইলাইট।
৪৪টি পেশাগত জ্ঞান-ভিত্তিক কাজের মূল্যায়ন করে জিডিপিভাল পরীক্ষায়, এটি মানব বিশেষজ্ঞদের সামগ্রিক কর্মক্ষমতা অর্জনকারী বা অতিক্রমকারী প্রথম মডেল হয়ে উঠেছে। বিশেষ করে, শিল্প বিশেষজ্ঞদের তুলনায়, GPT-5.2 চিন্তাভাবনা ৭০.৯% কাজে মানব বিশেষজ্ঞদের চেয়ে এগিয়ে গেছে বা তাদের সাথে মিলে গেছে।
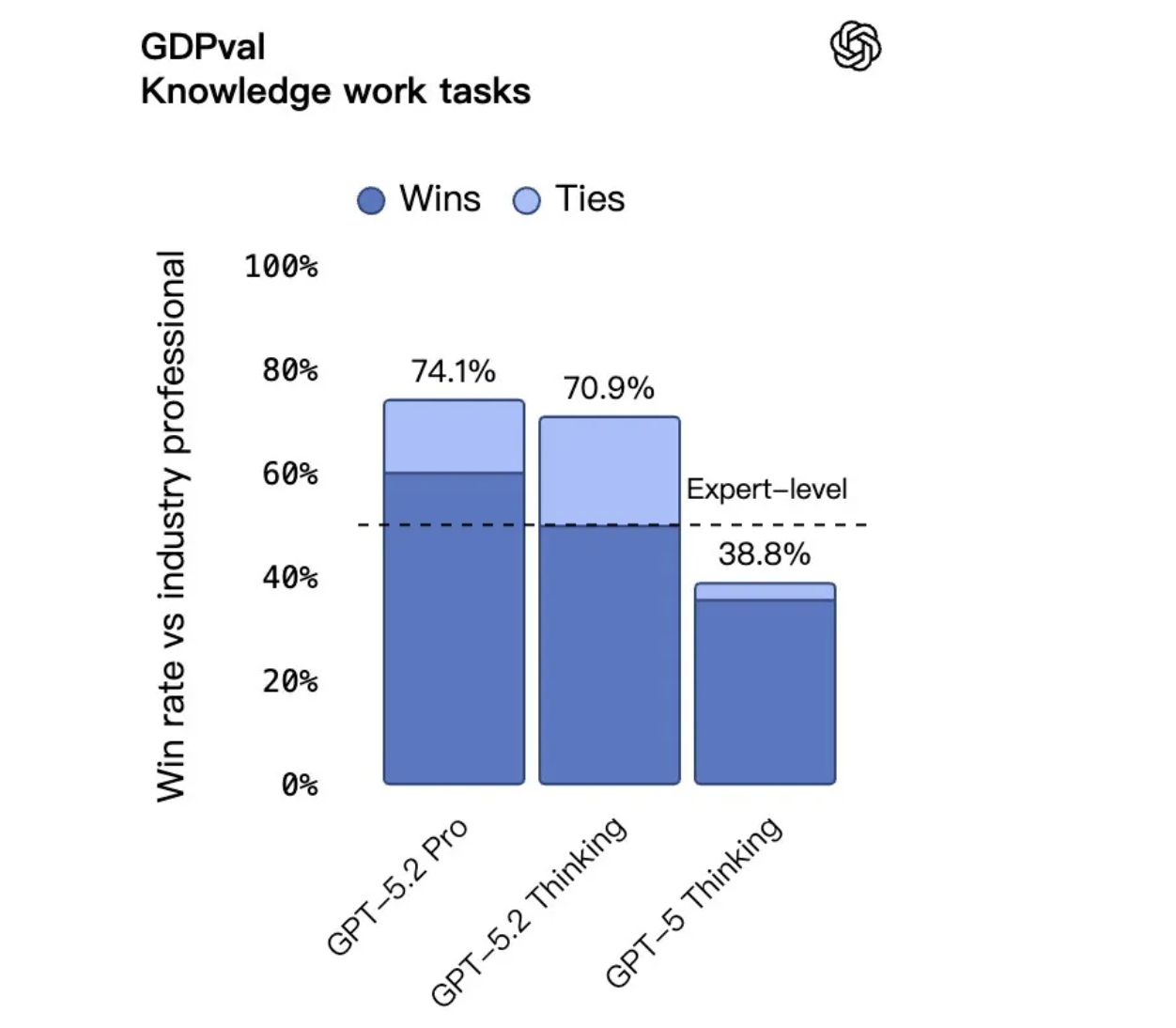
এই কাজগুলি স্বেচ্ছাচারী নয়; এগুলি মার্কিন জিডিপি র্যাঙ্কিংয়ের শীর্ষ নয়টি শিল্পকে অন্তর্ভুক্ত করে, যার মধ্যে রয়েছে বিক্রয় উপস্থাপনা, অ্যাকাউন্টিং বিবৃতি, জরুরি কক্ষের সময়সূচী পরিকল্পনা, উৎপাদন পরিকল্পনা, সংক্ষিপ্ত ভিডিও উৎপাদন এবং আরও অনেক কিছু – বাস্তব-বিশ্বের কাজের পরিস্থিতি থেকে সমস্ত কঠিন কাজ।
প্রোগ্রামিং দক্ষতার উন্নতি আরও লক্ষণীয়।
SWE-Bench Pro হল একটি অত্যন্ত কঠোর পরীক্ষা যা বাস্তব-বিশ্বের সফ্টওয়্যার ইঞ্জিনিয়ারিংয়ে একজন মডেলের ক্ষমতা মূল্যায়ন করে। এতে চারটি প্রোগ্রামিং ভাষা অন্তর্ভুক্ত এবং এটি পাইথন-কেবল সংস্করণের তুলনায় অনেক বেশি কঠিন। GPT-5.2 Thinking এই পরীক্ষায় 55.6% স্কোর অর্জন করেছে, যা একটি নতুন শিল্প রেকর্ড স্থাপন করেছে।
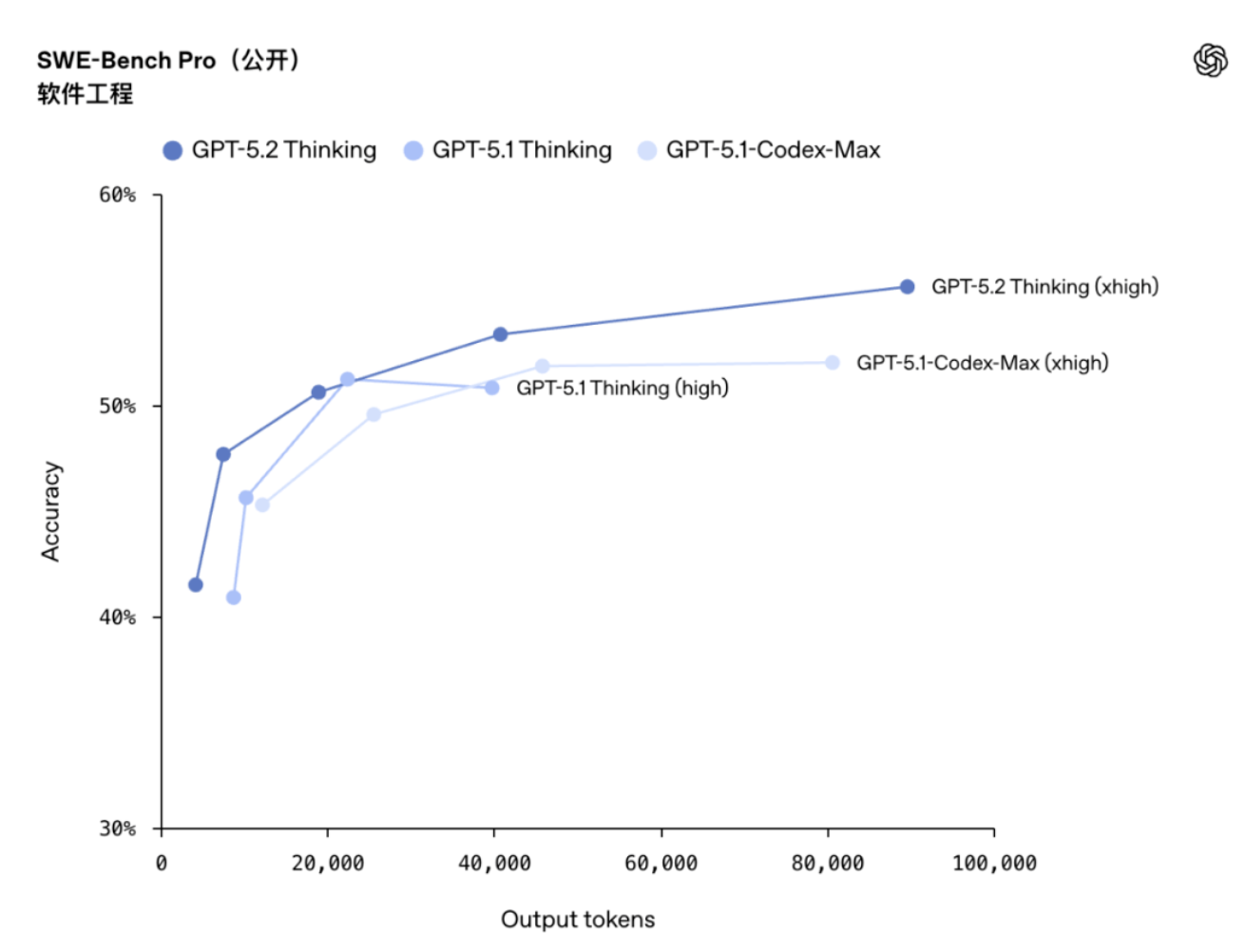
আরও চিত্তাকর্ষকভাবে, এটি SWE-বেঞ্চ ভেরিফাইডে ৮০% স্কোর অর্জন করেছে, যা একটি নতুন রেকর্ড স্থাপন করেছে। এর অর্থ হল GPT-5.2 থিংকিং উৎপাদন পরিবেশে আরও নির্ভরযোগ্যভাবে কোড ডিবাগ করতে পারে, কার্যকরী প্রয়োজনীয়তা বাস্তবায়ন করতে পারে এবং বৃহৎ কোডবেসগুলিকে রিফ্যাক্টর করতে পারে, যা এন্ড-টু-এন্ড ফিক্সগুলিকে আরও দক্ষ করে তোলে এবং মানুষের হস্তক্ষেপ হ্রাস করে।
ফ্রন্ট-এন্ড ডেভেলপমেন্টেও উল্লেখযোগ্য উন্নতি দেখা গেছে।
প্রাথমিক পরীক্ষকরা বলছেন যে জটিল বা অপ্রচলিত ফ্রন্ট-এন্ড UI কাজগুলি পরিচালনা করার সময় এটি আরও ভাল কার্য সম্পাদন করে, বিশেষ করে 3D উপাদানগুলির সাথে সম্পর্কিত, যা এটিকে ফুল-স্ট্যাক ইঞ্জিনিয়ারদের জন্য একটি সত্যিকারের সহকারী করে তোলে।
ওপেনএআই একটি একক প্রম্পট থেকে তৈরি বেশ কয়েকটি উদাহরণও প্রকাশ করেছে: একটি ওয়েভ সিমুলেটর, একটি ছুটির শুভেচ্ছা কার্ড জেনারেটর এবং একটি টাইপিং রেইন গেম। মাত্র একটি প্রম্পটের মাধ্যমে, একটি সম্পূর্ণ একক-পৃষ্ঠার অ্যাপ্লিকেশন তৈরি হয়, যা সামঞ্জস্যযোগ্য পরামিতি, বাস্তবসম্মত অ্যানিমেশন এবং একটি শান্ত UI স্টাইল সহ সম্পূর্ণ।
ইলিউশন রেট ৩০% কমেছে, দীর্ঘ লেখার ক্ষমতা প্রায় নিখুঁত।
বাস্তবিক নির্ভুলতার দিক থেকে, GPT-5.2 চিন্তাভাবনার GPT-5.1 চিন্তাভাবনার তুলনায় "ভ্রমের হার" কম।
বেনামী ChatGPT প্রশ্নের একটি সেটে, ভুল উত্তরের সংখ্যা প্রায় 30% কমেছে। পেশাদারদের জন্য, এটি ত্রুটির হার কমিয়ে এবং গবেষণা, লেখা, বিশ্লেষণ এবং সিদ্ধান্ত সহায়তার মতো কাজের জন্য পরিষেবাটি ব্যবহারের ক্ষেত্রে আরও আত্মবিশ্বাসের দিকে পরিচালিত করে।
যাইহোক, OpenAI আরও সতর্ক করে যে, সমস্ত মডেলের মতো, GPT-5.2 নিখুঁত নয়, এবং মূল কাজগুলির জন্য এখনও ম্যানুয়াল যাচাইকরণের প্রয়োজন হয়।
দীর্ঘ লেখার যুক্তি করার ক্ষমতাও একটি নতুন মানদণ্ড স্থাপন করেছে।
OpenAI MRCRv2 বেঞ্চমার্কে, GPT-5.2 GPT-5.1 কে ছাড়িয়ে গেছে। এই পরীক্ষাটি দীর্ঘ নথিতে বিতরণ করা তথ্য সঠিকভাবে সংহত করার জন্য একটি মডেলের ক্ষমতা মূল্যায়ন করে। গভীর নথি বিশ্লেষণের মতো কাজের জন্য, যেখানে লক্ষ লক্ষ টোকেন সহ ক্রস-ডকুমেন্ট তথ্য সংহত করা জড়িত, GPT-5.2 এর নির্ভুলতা GPT-5.1 এর চেয়ে অনেক বেশি।
বিশেষ করে MRCR 4-সুই পরীক্ষায় (যা "খড়ের গাদায় সূঁচ খুঁজে বের করা" থেকে আলাদা কিন্তু মডেলটিকে বিপুল পরিমাণে টেক্সটে একাধিক অভিন্ন "সুই" থেকে একটি নির্দিষ্টকে আলাদা করতে এবং খুঁজে বের করতে হয়), 256k টোকেন পর্যন্ত প্রেক্ষাপট সহ, GPT-5.2 হল প্রথম মডেল যা প্রায় 100% নির্ভুলতা অর্জন করে।
এর অর্থ হল পেশাদার ব্যবহারকারীরা GPT-5.2 ব্যবহার করে অত্যন্ত দীর্ঘ নথিগুলি দক্ষতার সাথে প্রক্রিয়া করতে পারেন, যার মধ্যে রয়েছে রিপোর্ট, চুক্তি, একাডেমিক পেপার, সাক্ষাৎকারের ট্রান্সক্রিপ্ট এবং মাল্টি-ফাইল প্রকল্প। এটি শত শত পৃষ্ঠার বিষয়বস্তু পরিচালনা করার সময়ও যৌক্তিক ধারাবাহিকতা এবং তথ্যের নির্ভুলতা বজায় রাখে। ভিজ্যুয়াল বোঝার ক্ষেত্রে, GPT-5.2 থিংকিং বর্তমানে OpenAI-এর সবচেয়ে শক্তিশালী ভিজ্যুয়াল মডেল। গ্রাফ রিজনিং এবং সফ্টওয়্যার ইন্টারফেস বোঝার ক্ষেত্রে, ত্রুটির হার প্রায় অর্ধেক কমে গেছে।
দৈনন্দিন পেশাদার ব্যবহারের জন্য, এর অর্থ হল মডেলটি ডেটা ড্যাশবোর্ড, পণ্যের স্ক্রিনশট, প্রযুক্তিগত অঙ্কন এবং ভিজ্যুয়াল প্রতিবেদনগুলিকে আরও সঠিকভাবে ব্যাখ্যা করতে পারে, যা এটিকে অর্থ, পরিচালনা, প্রকৌশল, নকশা এবং গ্রাহক পরিষেবার মতো দৃষ্টি-কেন্দ্রিক কাজের পরিস্থিতিতে উপযুক্ত করে তোলে।

স্থানিক বোঝাপড়া এবং সরঞ্জাম ব্যবহারের ক্ষমতাও উন্নত হয়েছে। Tau2-বেঞ্চ টেলিকম পরীক্ষায়, GPT-5.2 থিংকিং 98.7% এর একটি নতুন উচ্চ স্কোর অর্জন করেছে, যা দীর্ঘ, বহু-বৃত্তাকার কাজে নির্ভরযোগ্যভাবে সরঞ্জাম ব্যবহারের ক্ষমতা প্রদর্শন করে।
এমনকি অনুমান শক্তি সর্বনিম্ন স্তরে সেট করা সত্ত্বেও, GPT-5.2 এখনও GPT-5.1 এবং GPT-4.1-কে উল্লেখযোগ্যভাবে ছাড়িয়ে যায়।
এর অর্থ হল, GPT-5.2 চিন্তাভাবনা এন্ড-টু-এন্ড ওয়ার্কফ্লো সম্পাদন, গ্রাহক পরিষেবার কেস পরিচালনা, একাধিক সিস্টেম থেকে ডেটা আহরণ, বিশ্লেষণের কাজ সম্পাদন, সম্পূর্ণ প্রক্রিয়া আউটপুট দক্ষতার সাথে সম্পন্ন করা এবং মধ্যবর্তী পদক্ষেপগুলিতে ত্রুটি কমানোর ক্ষেত্রে আরও শক্তিশালী।
গণিত এবং বিজ্ঞানের দক্ষতা বৃদ্ধি সম্ভবত এই রিলিজের সবচেয়ে কঠিন অংশ।
GPQA Diamond-এর মতো স্নাতক-স্তরের বিজ্ঞান কুইজ পরীক্ষায়, যা পদার্থবিদ্যা, রসায়ন এবং জীববিজ্ঞানের মতো ক্ষেত্রগুলিকে অন্তর্ভুক্ত করে, GPT-5.2 উল্লেখযোগ্যভাবে ভালো পারফর্ম করে। এটি FrontierMath-এর মতো বেঞ্চমার্ক পরীক্ষাগুলিও পরিচালনা করতে পারে, যা বিশেষজ্ঞ-স্তরের গাণিতিক সমস্যা সমাধানের ক্ষমতা মূল্যায়ন করে।
আরও চিত্তাকর্ষকভাবে, ARC-AGI-1 পরীক্ষায়, GPT-5.2 Pro ছিল প্রথম মডেল যা 90% নির্ভুলতা অর্জন করেছে, গত বছরের o3-প্রিভিউয়ের 87% কে ছাড়িয়ে গেছে, একই সাথে খরচ প্রায় 390 গুণ কমিয়েছে।
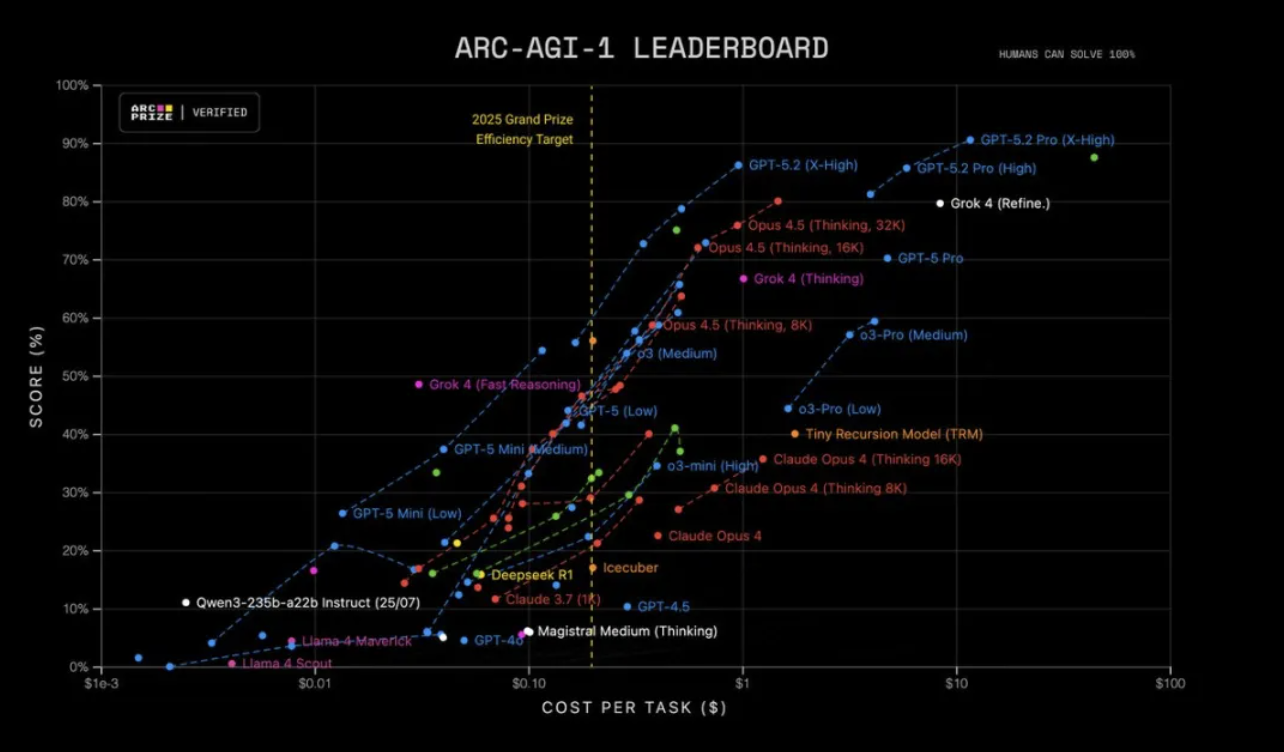
ARC-AGI-2 সংস্করণটি আরও কঠিন, যার মূল লক্ষ্য হল তরলতা যুক্তির ক্ষমতা পরীক্ষা করা। GPT-5.2 থিংকিং স্কোর 52.9%, যা "চেইন থিংকিং মডেল" এর জন্য একটি নতুন উচ্চতা স্থাপন করে। GPT-5.2 Pro আরও এগিয়ে যায়, 54.2% এ পৌঁছে।
অফিসিয়াল ব্লগে একটি চিত্তাকর্ষক উদাহরণের কথা উল্লেখ করা হয়েছে: GPT-5.2 Pro এমনকি পরিসংখ্যানগত শিক্ষা তত্ত্বে একটি উন্মুক্ত সমস্যার জন্য একটি সম্ভাব্য প্রমাণ প্রদান করে।
এই প্রশ্নটি ২০১৯ সালের লার্নিং থিওরি কনফারেন্স (COLT) এ উত্থাপিত একটি অমীমাংসিত সমস্যা থেকে এসেছে: যদি মডেলটি নিখুঁতভাবে কনফিগার করা থাকে এবং ডেটা একটি আদর্শ স্বাভাবিক বন্টন অনুসরণ করে, তাহলে এই পাঠ্যপুস্তকের "পরিষ্কার" ক্ষেত্রে কি শেখার বক্ররেখা একঘেয়ে?

গবেষকরা আগে থেকে কোনও অ্যালগরিদম ডিজাইন করেননি বা কোনও প্রমাণ প্রদান করেননি, এমনকি মধ্যবর্তী পদক্ষেপ বা ইঙ্গিতও দেননি। পরিবর্তে, তারা সরাসরি GPT-5.2 Pro থেকে সম্পূর্ণ প্রমাণের জন্য অনুরোধ করেছিলেন। ফলস্বরূপ, মডেলটি একটি সম্ভাব্য সমাধান প্রস্তাব করেছিল এবং ম্যানুয়াল যাচাইকরণ এবং বহিরাগত বিশেষজ্ঞ পর্যালোচনার মাধ্যমে এর সঠিকতা নিশ্চিত করা হয়েছিল।
এটি প্রমাণ করে যে GPT-5.2 Pro গণিত এবং তাত্ত্বিক কম্পিউটার বিজ্ঞানের মতো স্পষ্ট স্বতঃসিদ্ধ ভিত্তি সহ ক্ষেত্রগুলিতে বৈজ্ঞানিক গবেষণায় সহায়তা করার ক্ষেত্রে আরও গুরুত্বপূর্ণ ভূমিকা পালন করতে পারে: প্রমাণ পথ অন্বেষণ, অনুমান যাচাই এবং লুকানো সংযোগ আবিষ্কার।
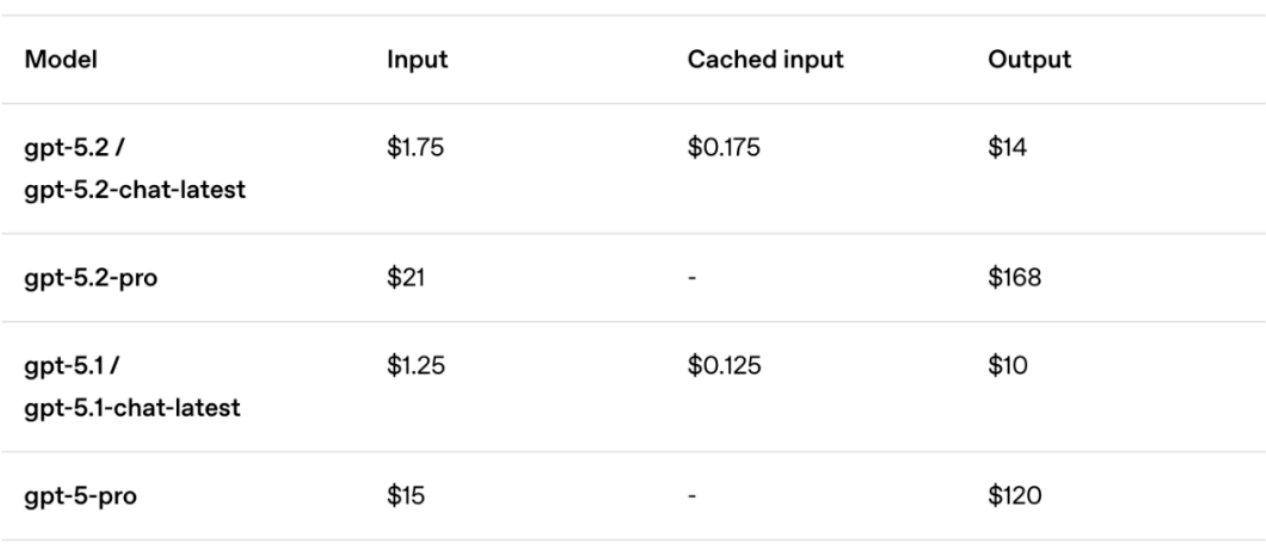
▲GPT-5.2 API মূল্য
এত চিত্তাকর্ষক পারফরম্যান্সের দাম অনেক বেশি।
থিংকিং এবং ডিপ রিসার্চ মোডগুলি সাধারণ চ্যাটবটগুলির তুলনায় অনেক বেশি কম্পিউটিং শক্তি ব্যবহার করে কারণ তাদের আরও গভীরভাবে "চিন্তা" করতে হয়। এর কারণ হল OpenAI এখন মাইক্রোসফ্ট অ্যাজুরে ক্লাউড সার্ভিস ক্রেডিট ব্যবহার করার পরিবর্তে মডেল ইনফারেন্সের জন্য তার বেশিরভাগ সম্পদ সরাসরি নগদে ব্যয় করে।
এই ধরণের কৌশল, যার মধ্যে ক্রমাগত অর্থ ঢালা থাকে, কতদিন স্থায়ী হতে পারে তা বলা কঠিন।
সামগ্রিকভাবে, GPT-5.2 সম্পূর্ণ পুনর্গঠনের চেয়ে আগের দুটি মডেল আপগ্রেডের একীকরণের মতো।
আগস্টের GPT-5 ছিল একটি স্থাপত্যিক রিবুট, যা একটি রাউটিং প্রক্রিয়া প্রবর্তন করে যা দ্রুত প্রতিক্রিয়া এবং গভীর "চিন্তা" মোডের মধ্যে স্যুইচ করার অনুমতি দেয়। নভেম্বরের GPT-5.1 সিস্টেমটিকে আরও মৃদু, আরও কথোপকথনমূলক এবং এজেন্ট এবং কোডিং কাজের জন্য আরও উপযুক্ত করে তুলেছে।
বর্তমান GPT-5.2 এর লক্ষ্য হল এই সুবিধাগুলির উপর ভিত্তি করে আরও নির্ভরযোগ্য উৎপাদন-গ্রেড মডেল তৈরি করা। এবং একটি অত্যন্ত গুরুত্বপূর্ণ বিশদ: এইবার প্রকাশিত তিনটি GPT-5.2 মডেলের অন্তর্নিহিত জ্ঞানের ভিত্তি আপডেট করা হয়েছে।

GPT-5.2 ধীরে ধীরে ChatGPT-তে চালু হতে শুরু করেছে, প্রাথমিকভাবে অর্থপ্রদানকারী ব্যবহারকারীদের জন্য উপলব্ধ। GPT-5.1 আনুষ্ঠানিকভাবে বন্ধ হওয়ার আগে তিন মাস "ট্র্যাডিশনাল মডেল" বিকল্পে থাকবে।
APIটিও উপলব্ধ, এবং ডেভেলপাররা ইতিমধ্যেই এটি ব্যবহার করতে পারেন। এটি GPT-5.1 এর তুলনায় কিছুটা বেশি ব্যয়বহুল, কিন্তু OpenAI বলে যে টোকেনটি বেশি দক্ষ হওয়ায়, প্রকৃত মোট খরচ কম।
একটা খারাপ খবর আর একটা ভালো খবর
মডেলটি ছাড়াও, OpenAI-এর বাণিজ্যিকীকরণ সম্পর্কিত দুটি অত্যন্ত বিপরীত খবর রয়েছে।
যদিও এই রিলিজে কোনও নতুন ইমেজ জেনারেশন মডেল চালু করা হয়নি, OpenAI আজ ডিজনির সাথে তিন বছরের লাইসেন্সিং চুক্তিতে পৌঁছেছে।
ব্যবহারকারীরা ডিজনি, মার্ভেল, পিক্সার এবং স্টার ওয়ার্সের ২০০ টিরও বেশি চরিত্রের সোশ্যাল ভিডিও তৈরি করতে পারেন এবং এর মধ্যে কিছু ভিডিও ডিজনি+ এও চালানো যেতে পারে।
বিনিময়ে, ডিজনি ওপেনএআই-তে ১ বিলিয়ন ডলার বিনিয়োগ করেছে এবং একটি প্রধান গ্রাহক হয়ে উঠবে। কন্টেন্ট আইপি এবং এআই জেনারেশনের সমন্বয় অবশ্যই প্রচুর সম্ভাবনা প্রদান করে।

আরেকটি উল্লেখযোগ্য খবর হল যে ChatGPT-এর "প্রাপ্তবয়স্ক মোড" অবশেষে একটি স্পষ্ট সময়রেখা পেয়েছে।
প্রাপ্তবয়স্কদের কন্টেন্টে ক্রমবর্ধমান সংখ্যক AI চ্যাটবট প্রবেশ করায়, OpenAI আর সেই সন্ত হিসেবে কাজ করছে না। ব্লুমবার্গের মতে, ফিদজি সিমো নিশ্চিত করেছেন যে এই বৈশিষ্ট্যটি ২০২৬ সালের প্রথম প্রান্তিকে চালু হবে বলে আশা করা হচ্ছে।
এর আগে, OpenAI তার বয়স শনাক্তকরণ ক্ষমতাগুলিকে অপ্টিমাইজ করে রাখবে যাতে নাবালকদের জন্য কন্টেন্ট সুরক্ষা ব্যবস্থা স্বয়ংক্রিয়ভাবে সক্রিয় হয়। বর্তমানে, কিশোর-কিশোরীদের শনাক্ত করার ক্ষমতা মূল্যায়ন করার জন্য এবং এটি যাতে প্রাপ্তবয়স্কদের ভুল শনাক্ত না করে তা নিশ্চিত করার জন্য নির্বাচিত দেশগুলিতে বয়স পূর্বাভাস মডেলটির প্রাথমিক পরীক্ষা চলছে।
গুগল জেমিনির নিরলস চাপের মুখে, ওপেনএআই জিপিটি-৫.২ সহ বিভিন্ন পদক্ষেপের সমন্বয়ে সাড়া দিয়েছে। এটি দ্রুত, শক্তিশালী এবং একটি পরিপক্ক বাণিজ্যিক পণ্যের মতো।
একই সাথে, ডিজনির মিকি মাউসকে আলিঙ্গন করার সাথে সাথে, ওপেনএআই একটি প্রাপ্তবয়স্ক মোড চালু করার প্রস্তুতিও নিচ্ছে। তাদের প্রযুক্তিগত নেতৃত্ব বজায় রাখতে হবে এবং দ্রুত তাদের পণ্যগুলি নগদীকরণ করতে হবে; তাদের এন্টারপ্রাইজ বাজার দখল করতে হবে এবং কোনও ট্র্যাফিক প্রবেশের পয়েন্ট ছাড়তে হবে না।
সৌভাগ্যবশত, ওপেনএআই, যা তার দশম বার্ষিকী উদযাপন করছে, শেষ পর্যন্ত এই পাল্টা আক্রমণে ভালো প্রদর্শন করেছে।
▲ এখানে একটি ছোট ইস্টার এগও আছে
#iFanr-এর অফিসিয়াল WeChat অ্যাকাউন্ট অনুসরণ করতে আপনাকে স্বাগতম: iFanr (WeChat ID: ifanr), যেখানে যত তাড়াতাড়ি সম্ভব আরও উত্তেজনাপূর্ণ কন্টেন্ট আপনার কাছে উপস্থাপন করা হবে।